

※Taggerはエラーが出て入れられないことがあるので、こちらにある「Iinfinite Image Browsing」で代用できる。
または以下の通りにすればTaggerを入れられる。
Tagger のインストール方法
開発者のトリアート氏は 2023年11月に開発から、撤退されていますので、アップデートに対応できて、いないようです。
しかしここから出来るはずです 先月はインストール出来た c:\StableDeffushion※※\stable-diffusion-webui\extensionsからTaggerのファイルを削除して https://github.com/Kataragi/stable-diffusion-webui-tagger-fork から 緑色のcode▽をクリック https://github.com/Kataragi/stable-diffusion-webui-tagger-fork.git をコピーして Stable Diffusionのextensionsからインストールして再起動でいけます。 動作確認済みです。 これでエラーが出たら???です。
- Tag complete
- Easy Prompt Selector
- Iinfinite Image Browsing
- sd_katanukiとは?
- traintrain を入れる時の注意点
- sd-webui-traintrain で簡単LoRA作り!
- 1.LoRAを作るために必要なもの
- 2.学習させる画像についての注意点
- 3.LoRAを作る流れ
- 4. sd-webui-traintrain のインストール
- 5.stable-diffusion-webui-dataset-tag-editorのインストール
- 6.画像からタグを抽出して整える(Dataset Tag Editorでの作業)
- 7.LoRAの作成(TrainTrainでの作業)
- 8.検証
- 9.まとめ
- 高機能画像編集アプリ「Photopea」の概要
- 超高機能画像編集アプリ「Photopea」を「Stable Diffusion web UI」で利用する
- 拡張機能「HakuImg」とは?
- 拡張機能「HakuImg」の導入方法
- 拡張機能「HakuImg」の使い方
- Stable Diffusionの『ワイルドカード』とは?
- 『ワイルドカード』の使い方
- テキストファイルを使わないで『ワイルドカード』を使用する場合
- 「Wildcards Manager」を使う方法
- まとめ
Tag complete
プロンプトの予測表示。
Google検索にある、Googleサジェスト(オートコンプリート)に似た機能。
面倒なプロンプト入力を簡単にする。
同時に、予測語が出ることで、英単語のちょっとしたスペルミスがなくなります。
インストール方法
- Extensions
- Install from URL
- URL for extension’s git repository
上記の窓にURLを入力してインストールボタンを押下。
画面下の「Reload UI」で有効化。
a1111-sd-webui-tagcompleteが、Installedに出る。
使い方
プロンプト入力窓で適当に文字を入れると、予測語が表示される。
Easy Prompt Selector
よく使う単語をグループ分けしておいて、マウス選択で入力していける。
この際に、次の単語をマウス選択すると、自動的にカンマ区切りになるところも気が利いている。
チェックボックスで、ネガティブプロンプト側にプロンプトを入れられるのも便利。
yml形式で内容をカスタマイズできる。
インストール方法
- Extensions
- Install from URL
- URL for extension’s git repository
上記の窓にURLを入力してインストールボタンを押下。
画面下の「Reload UI」で有効化。
sdweb-easy-prompt-selectorが、Installedに出る。
使い方

タグを選択から利用。
Iinfinite Image Browsing
生成した画像の一括閲覧と管理。
便利なところが、画像とともにプロンプトや生成した時の条件を確認できるところ。
生成画像が増えてくると、この画像の設定を忘れたなぁということが増えるはずですが、GUIで管理しやすくなります。
インストール方法
- Extensions
- Install from URL
- URL for extension’s git repository
上記の窓にURLを入力してインストールボタンを押下。
画面下の「Reload UI」で有効化。
sd-webui-infinite-image-browsingが、Installedに出る。
使い方の例

- Launch from Quick Move
- working folder
- output
- 日付フォルダを選択
sd_katanukiとは?

『sd_katanuki』は、冒頭にも紹介しましたが『Stable Diffusion WebUI』の拡張機能になります。
導入方法などは書いているので開かなくて大丈夫ですが、内容の更新などがあるかもしれないので、いちおう公式リンクものせておきます!
公式リンク
GitHub
sd_katanukiの導入方法

それでは『sd_katanuki』の導入方法をご紹介します!
まずは通常の拡張機能と同じ操作で「Extensions/拡張機能」のタブから機能を追加します。
操作がわかる人は以下のURLでインストール、わからない人は『詳しい操作方法はこちら』のタブを開くと操作方法がわかるようにしました。
URL
https://github.com/aka7774/sd_katanuki.git
~詳しい操作方法はこちら~
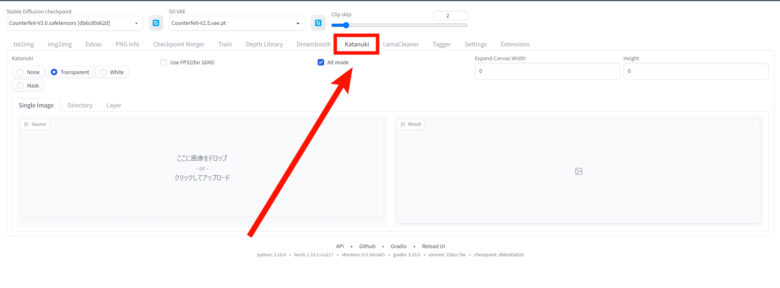
拡張機能のダウンロードが完了すると、タブの中に『katanuki』ができます。
これで『sd_katanuki』の導入完了です!
sd_katanukiの使い方
これで『sd_katanuki』の使い方についてです!
画像生成するimg2imgのタブ内の『Script』からもできますが、設定箇所が増えて操作が大変になるので『katanuki』タブでの操作方法をご紹介します!
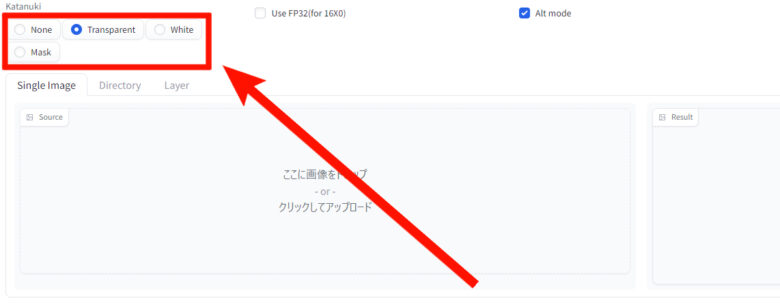
『katanuki』タブ内の左上に4つの選べるタブがあります。
タブによって行われる処理が変わりますが『None』は無処理なので使いません。
各処理の違い



- Transparent
- 背景透過機能
- White
- 白背景へ変換
- Mask
- ControlNetのDepthなどで使えるマスク画像生成
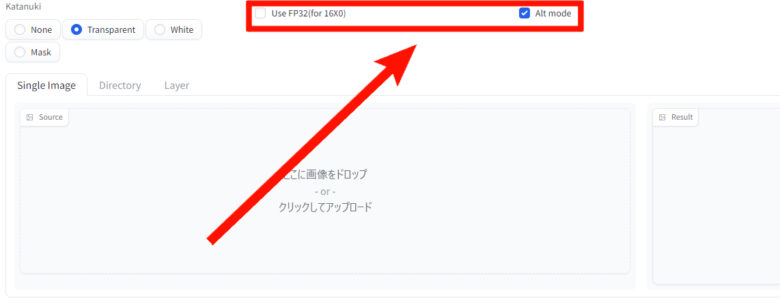
『katanuki』タブ内にチェックをつけれる項目が二つあります。
- Use FP32(for 16X0)
- グラフィックボードがRTX16X0の場合にチェックする
- Alt mode
- 基本的にはチェックを入れる。白背景にした時など変換に異常があれば外す
これで基本的な設定は完了になるので、どういう風に変換したいかを選んで処理できます。
~Single Image~
『Single Image』は、1枚の画像を変換したい時に使います。
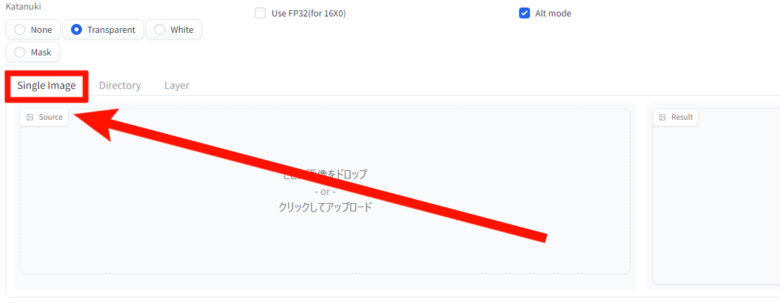
『katanuki』タブ内の『Single Image』を選びます。
あとは画像をアップロードすると選んだ処理で自動的に変換されます。
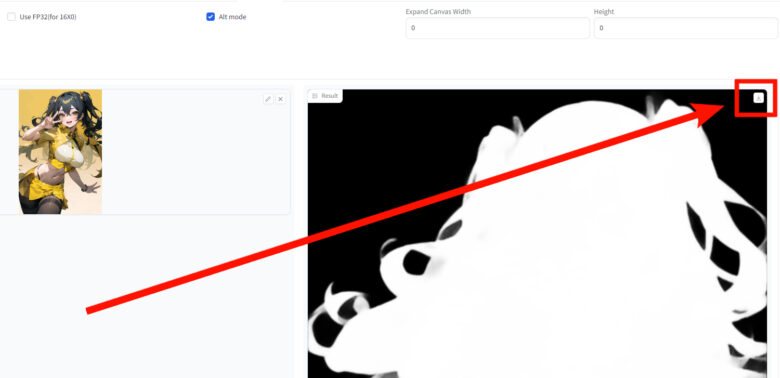
変換が終わったら下向き矢印マークを押すと画像の保存が可能です。
~Directory~
『Directory』は、複数の画像を同時に変換することができる機能になります。
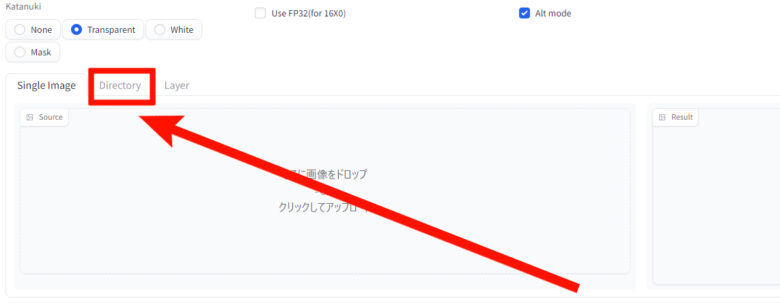
『katanuki』タブ内の『Directory』を選びます。
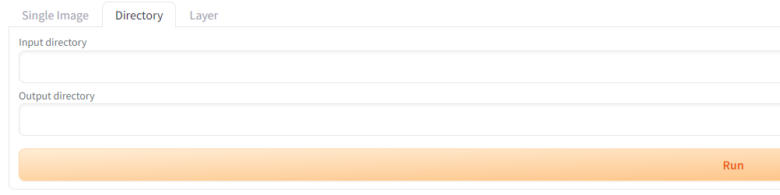
『Input directory』と『Output directory』の二つの入力欄がでます。
『Input directory』には画像が入っているフォルダのパス、『Output directory』には変換した画像を保存するフォルダのパスを入力します。
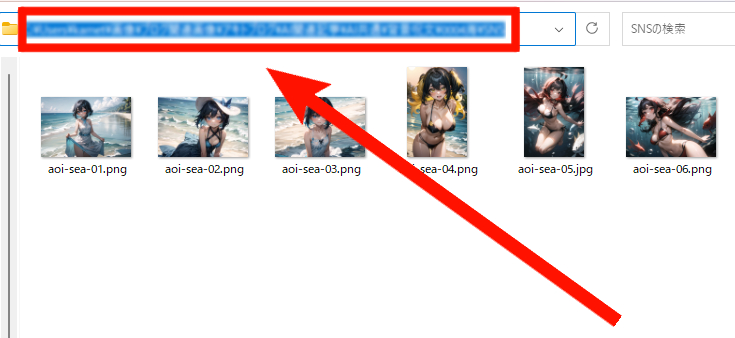
フォルダのパスを入力したら『Run』を押せば処理が開始され、『Output directory』に指定したフォルダに画像が保存されます。
~Layer~
二つの画像を合成できる機能のようですが、使用するとエラーが起きてしまいました。
製作者様のReadmeを読んでも使い方が書いていないので、新しい情報が入ったら記事を追記します!
Layerの使い方等が分かる人がいたら、記事のコメントかDMで教えていただけると嬉しいです!
以上が『sd_katanuki』の使い方です!
~sd_katanukiの使用例~
切り抜き精度が高いので一般的な『Lora』などの学習にも使えますし、用意した背景と人物を合わせたりに使えます。
traintrain を入れる時の注意点
通常は以下、「sd-webui-traintrain で簡単LoRA作り!」でそのまま入れられるが、『Stable Diffusion WebUI(Forge版)』では
Commit hash: 9001968898187e5baf83ecc3b9e44c6a6a1651a6
だと稼働しなくなったことが分かる(2024.09.下旬)。
そこで、
29be1da7cf2b5dccfc70fbdd33eb35c56a31ffb7
まで遡れば使えるので、そのように。基本的には(↓)このやり方でできるのだが、そのままではできない。

そこで、以下のgitファイル「.git-blame-ignore-revs」がある場所(↓:C:\Users\Alpaca\Documents\webui_forge_cu121_torch231\webui)まで降りていき、
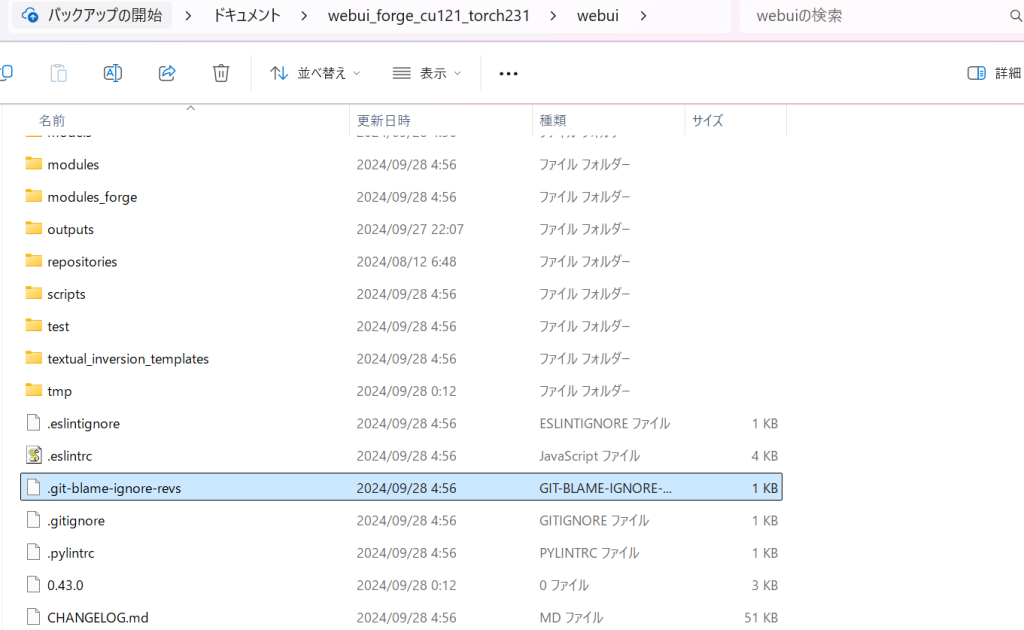
同じようにコマンドプロンプトを開いてこちらを入力。
> ..\system\git\bin\git reset –hard 29be1da7cf2b5dccfc70fbdd33eb35c56a31ffb7

これで使えるようになる。うまくいかない場合はコードが微妙に違っているか、『Stable Diffusion WebUI(Forge版)』を閉じてからやっていないなど何かしらちょっとした違いがあるはず。
基本的にはこちら(↓)を参照のほど。

sd-webui-traintrain で簡単LoRA作り!

1.LoRAを作るために必要なもの
必要なものは、以下のとおりです。
- Stable Diffusion WebUI(AUTOMATIC1111)
- Dataset Tag Editor(拡張機能)
- TrainTrain(拡張機能)
- 学習させる画像
Stable Diffusion WebUI(AUTOMATIC1111)に2つの拡張機能をインストールする必要があります。拡張機能のインストールは、非常に簡単で時間もかかりません。
各拡張機能のインストールについては、後述の「4. sd-webui-traintrain のインストール」「5.stable-diffusion-webui-dataset-tag-editorのインストール」で解説します。
2.学習させる画像についての注意点
LoRA作成で一番重要なものは学習させる画像です。
ここで手を抜くと良いLoRAは作れません。
学習させる画像については、できるだけ綺麗な画像を最低10~20枚程度準備します。
画像の大きさは、512*512 または 1024*1024 を基本にします。
縦長や横長の画像が混在していても学習可能です。
画質が荒いと、その画質の荒さまで学習してしまうことがあるので注意が必要です。
ネットからダウンロードした写真やスマホのゲーム画面のスクショなどは学習画像に向きません。
高画質なものであれば問題ありませんが、大抵の場合、画質が荒いです。元々画質が荒い画像を無理に大きくすると余計に画質が荒れてしまいます。
Stable Diffusionで学習画像を生成する場合には、Hires.Fix(高解像度補助)などを施した方が良いと思います。
以前、実写系のLoRAを作成した際、Hires.Fixを施していない画像を使用したところ、瞳の形やまつ毛、肌の質感などにかなりの悪影響が出ました。
実写系の場合は、無加工の写真データやプリントした写真を高解像度スキャンして使用する方法が良いかもしれません。
今回は、以下の16枚のイラスト画像(大きさは1024*1024)を使用してLoRAを作成します。

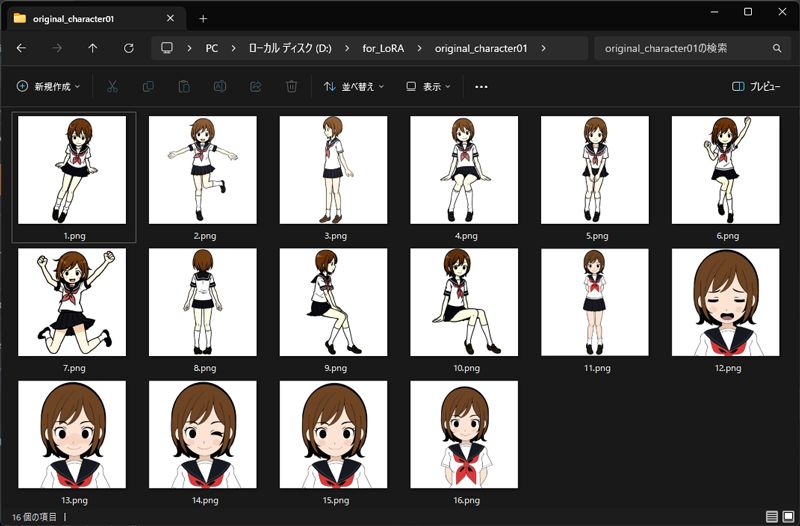
3.LoRAを作る流れ
LoRA作成の流れは、ザックリ以下の3つです。
- 学習させる画像を準備する(前述のように、多分これが一番大変)
- 画像からタグを抽出して整える(Dataset Tag Editorを使用)
- LoRAの作成(TrainTrainを使用)
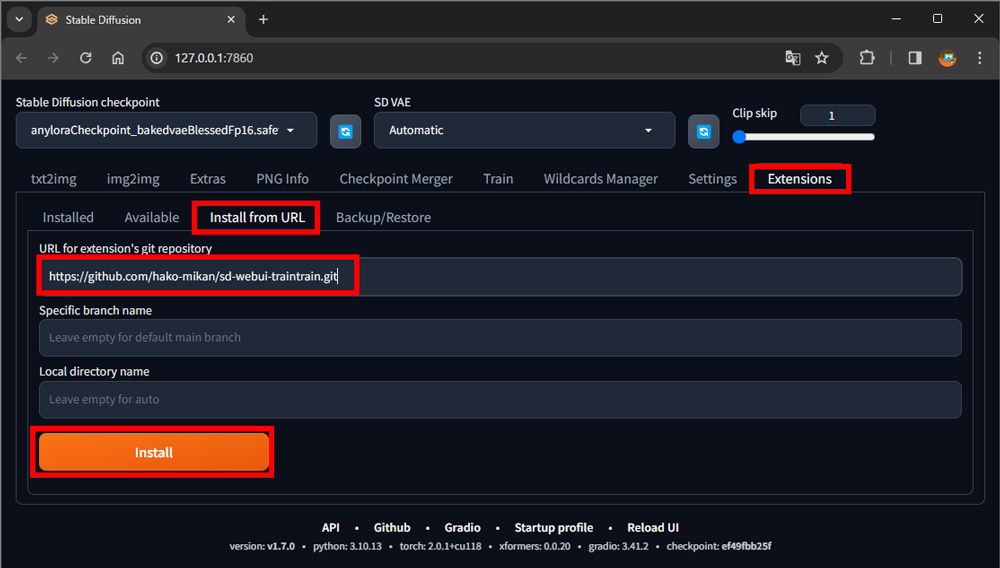
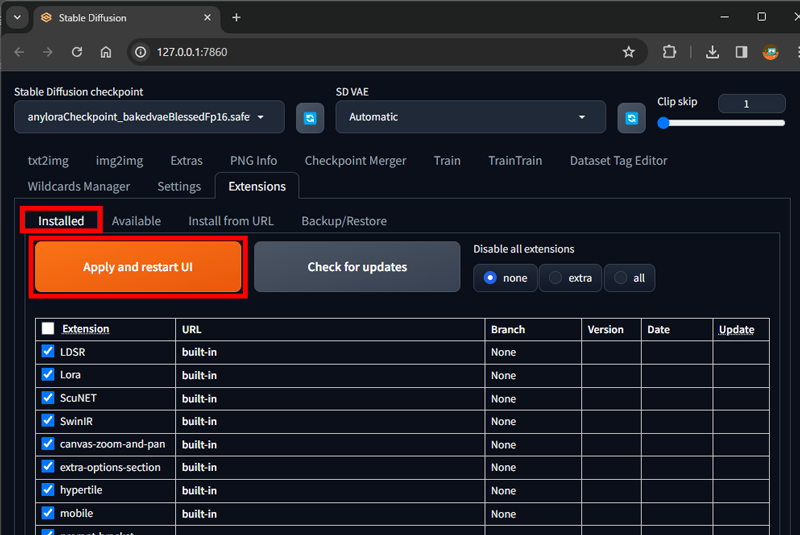
4. sd-webui-traintrain のインストール
1.Extensionsタブを選択
2.Install from URLタブを選択
3.URL for extension’s git repository欄に以下のURLをペースト
https://github.com/hako-mikan/sd-webui-traintrain.git
4.Installボタンをクリック
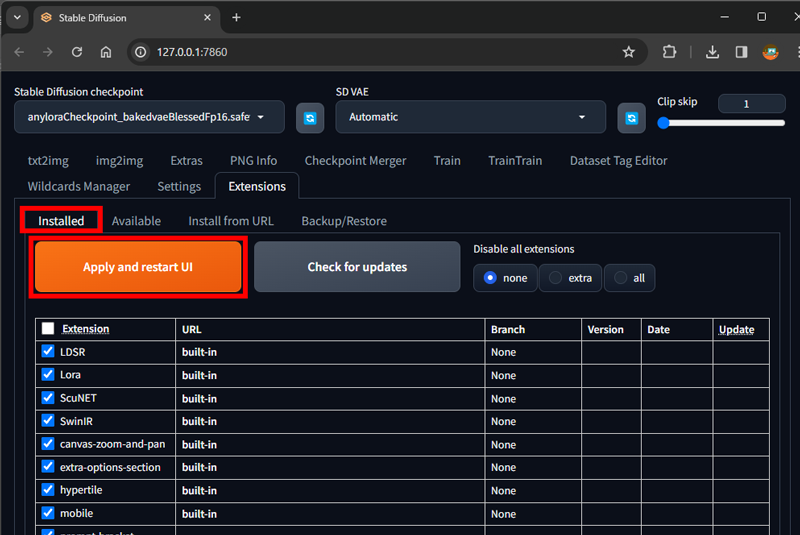
5.Installedタブを選択
6.Apply and restart UIボタンをクリック
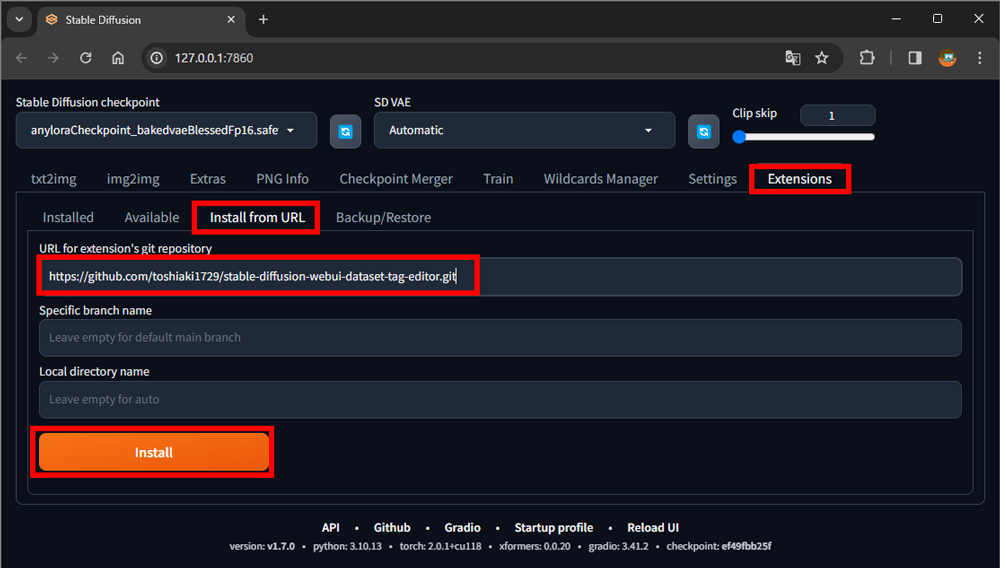
5.stable-diffusion-webui-dataset-tag-editorのインストール
1.Extensionsタブを選択
2.Install from URLタブを選択
3.URL for extension’s git repository欄に以下のURLをペースト
https://github.com/toshiaki1729/stable-diffusion-webui-dataset-tag-editor.git
4.Installボタンをクリック
5.Installedタブを選択
6.Apply and restart UIボタンをクリック
6.画像からタグを抽出して整える(Dataset Tag Editorでの作業)
Dataset Tag Editorを使って、画像からタグを抽出し、「学習させたいタグを消去」します。
こうして整えたタグをテキストファイルとして書き出します。
タグの抽出、タグの消去、テキストファイル書き出しは、全てDataset Tag Editorで行います。
6-1.画像を任意のフォルダにまとめる
準備した画像を任意のフォルダにまとめておきます。この例では、以下のフォルダ内に画像をまとめてあります。
d:\training\original_character01
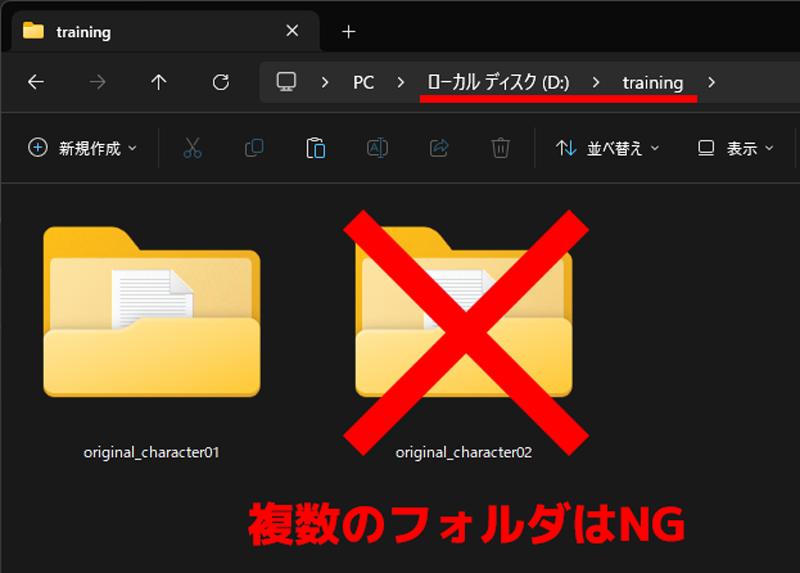
LoRAを作成する際、画像を保存したフォルダの一つ上の階層を指定する必要があるので、CドライブやDドライブなどの直下のフォルダではなく、training などの任意のフォルダを作成してから、その中にもう一つフォルダを作成して画像をまとめておきます。
また、フォルダを複数作成しないようにしてください。
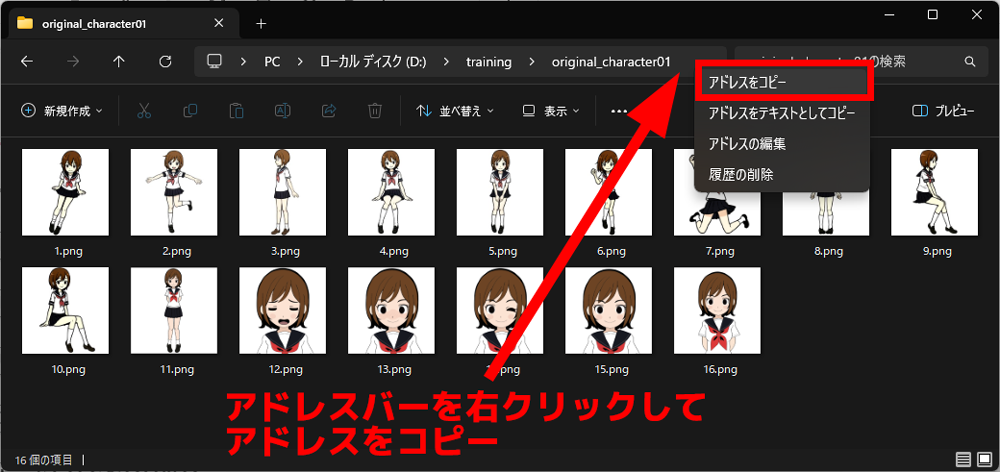
6-2.画像からタグを抽出する
⓪.画像フォルダのアドレスをコピー
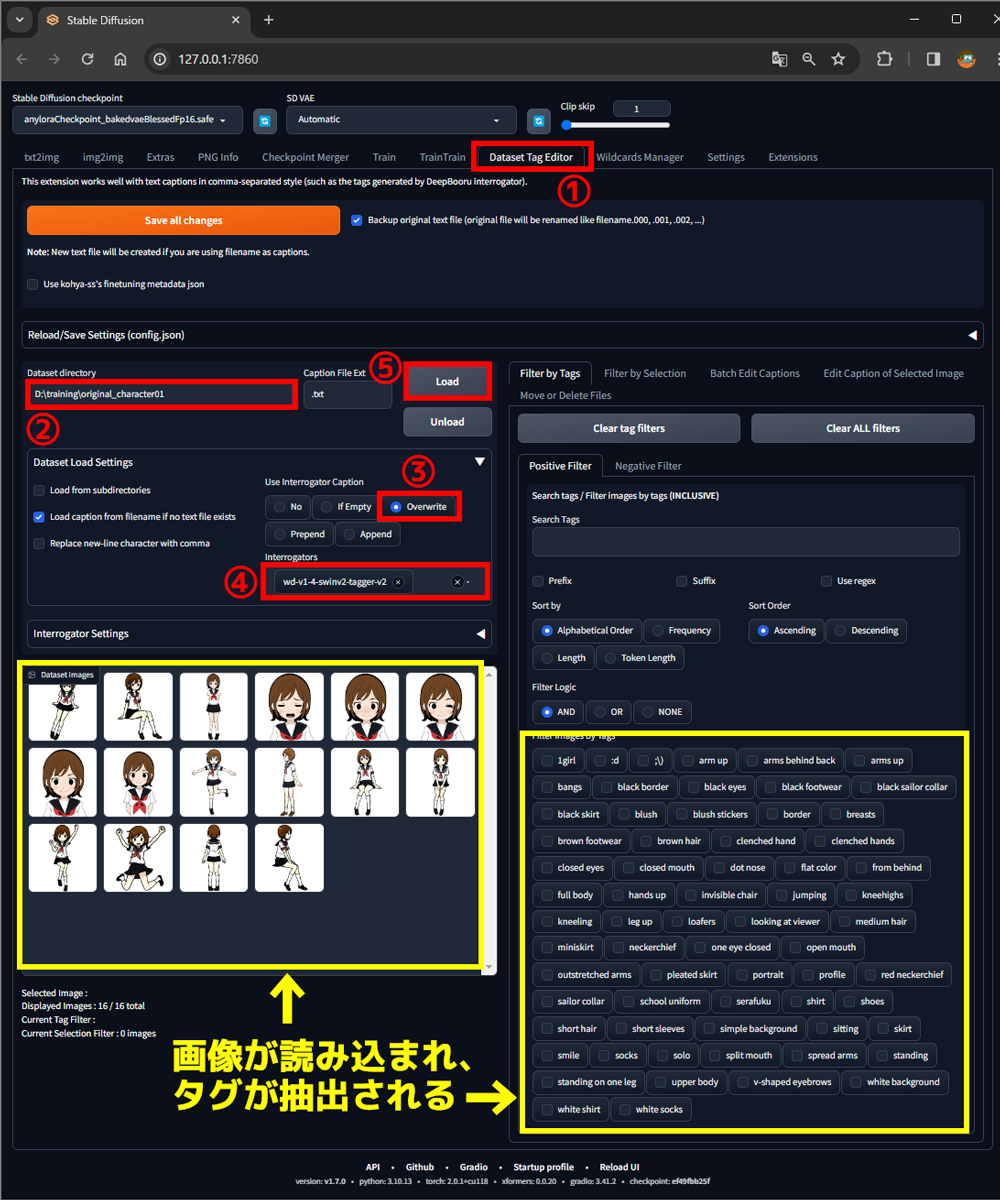
①Dataset Tag Editorタブを選択
②Dataset directory欄に先ほどコピーした画像フォルダのアドレスを貼り付け
③Use Interrogator CaptionをOverwriteに変更
④Interrogators欄で wd-v1-4-*** のいずれかを選択
⑤Loadボタンをクリック
Loadボタンを押すと画像と画像から抽出したタグが表示されます。(黄枠内)
6-3.学習させたいタグを選択して消去する
①Batch Edit Captionsタブを選択
②Removeタブを選択
③タグ一覧から学習させたいタグを選択
④Remove selected tagsボタンをクリック
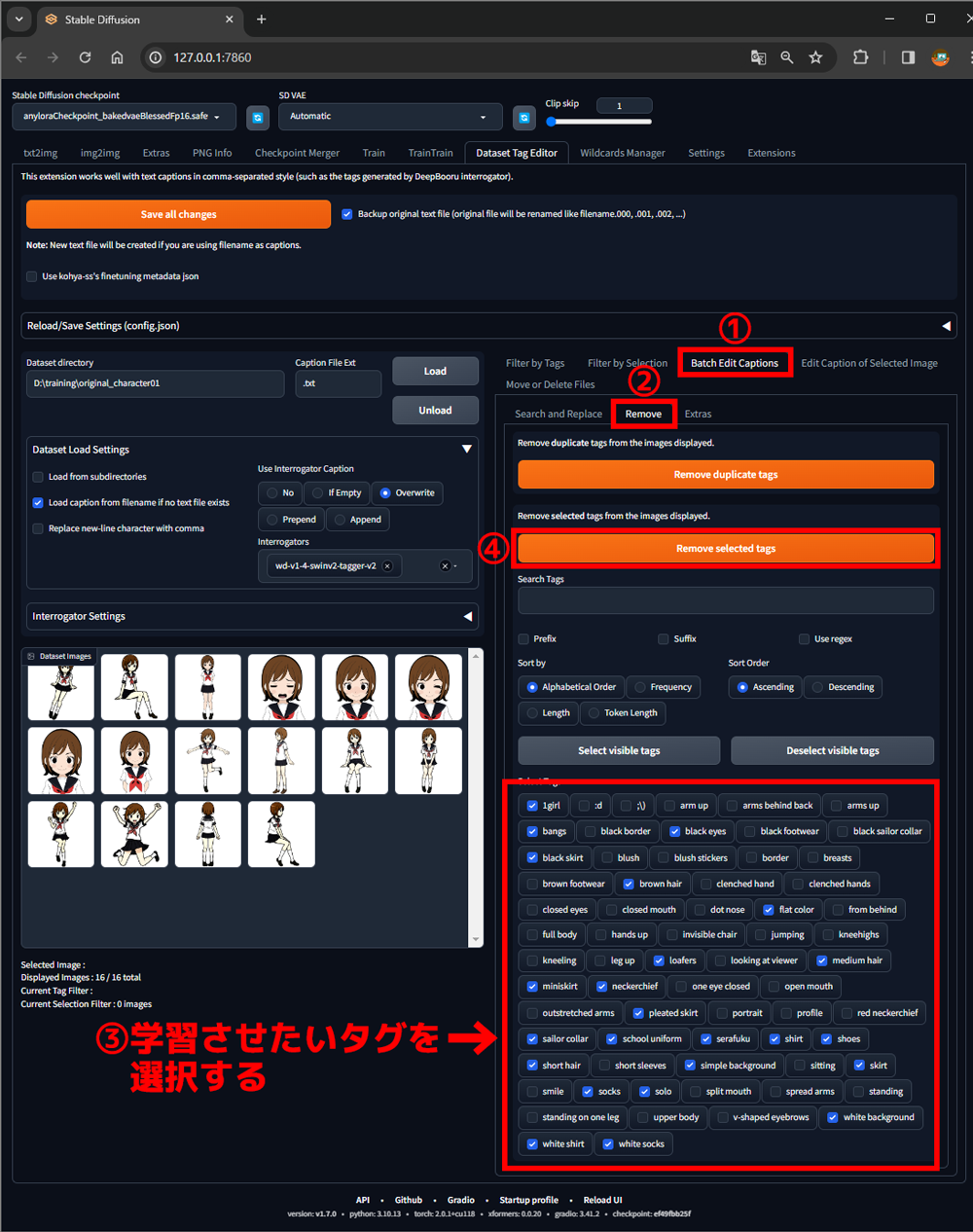
下のように選択したタグが一覧から消去されました。
タグの数が多い場合は、見落としがあるので③と④を繰り返して学習させたいタグを全て消去します。
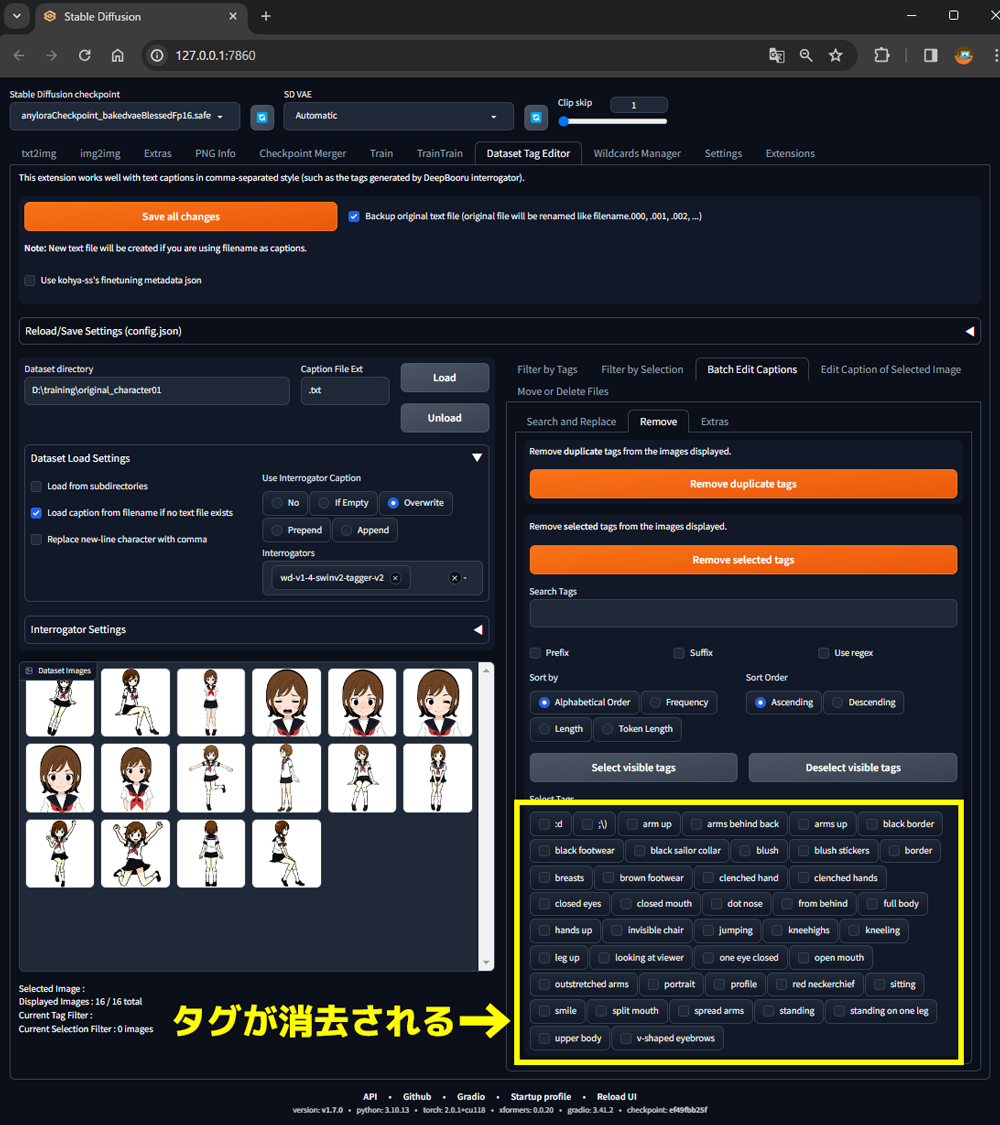
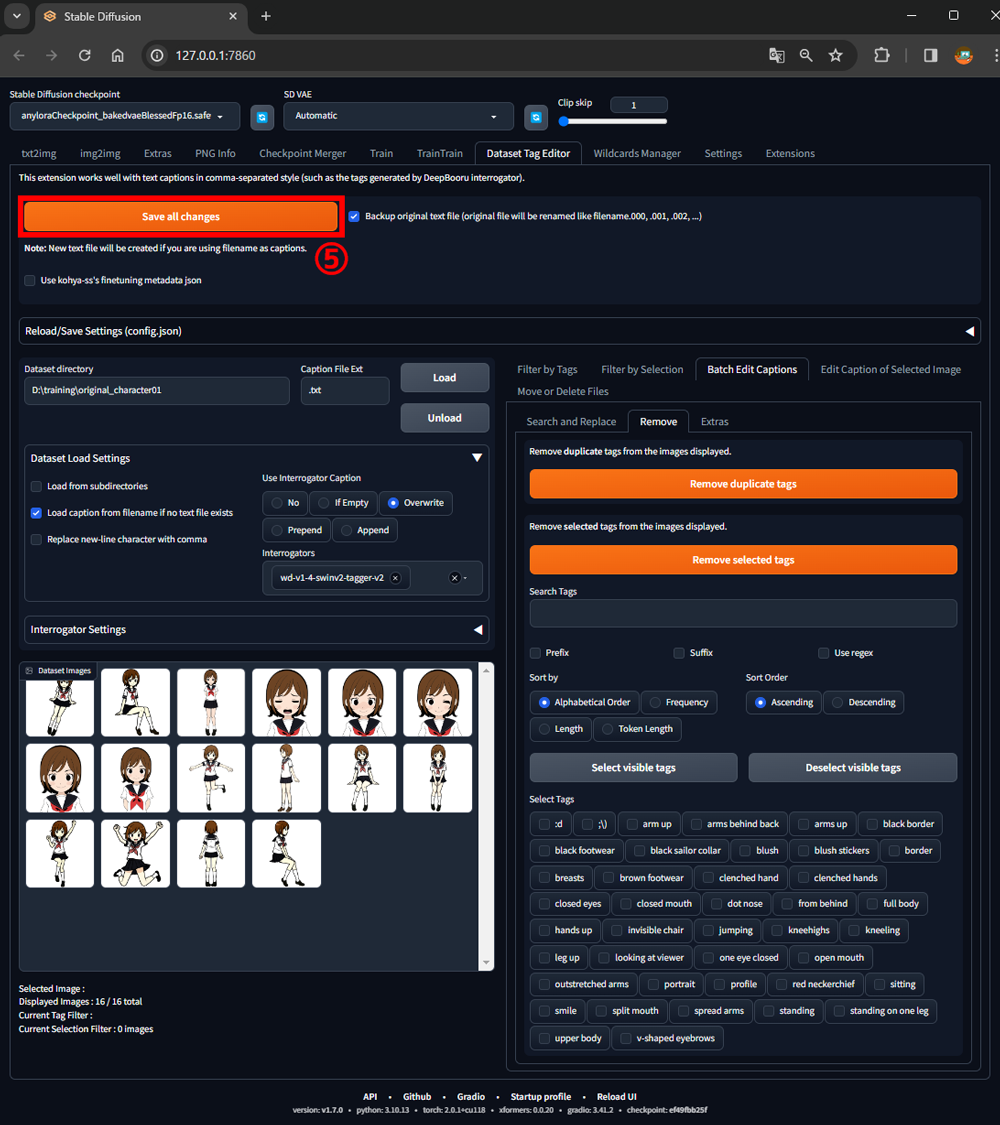
⑤Save all changesボタンをクリック
このボタンを押すとタグをテキストファイルとして書き出してくれます。
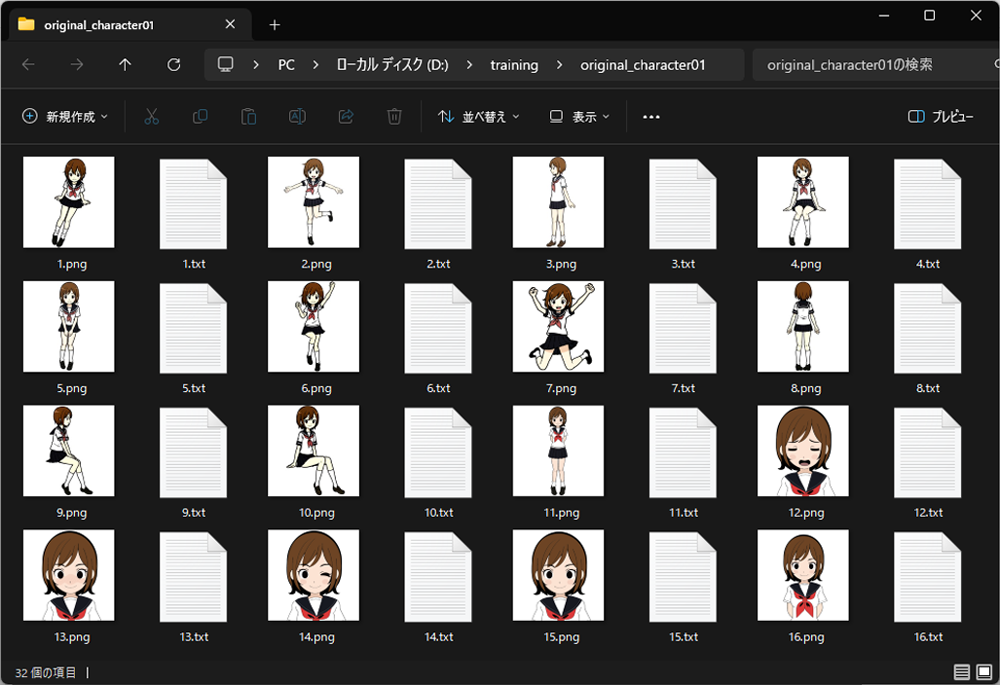
画像フォルダ内にテキストファイルが作成されました。
それぞれのテキストファイルには、学習させたいタグが消去されたプロンプトが記述されています。
これでLoRAを作る準備が整いました。
7.LoRAの作成(TrainTrainでの作業)
今回は、ほぼ標準設定のままでLoRAを作成してみます。
⓪画像フォルダの一つ上の階層のアドレスをコピー
この例では、D:¥training となります。
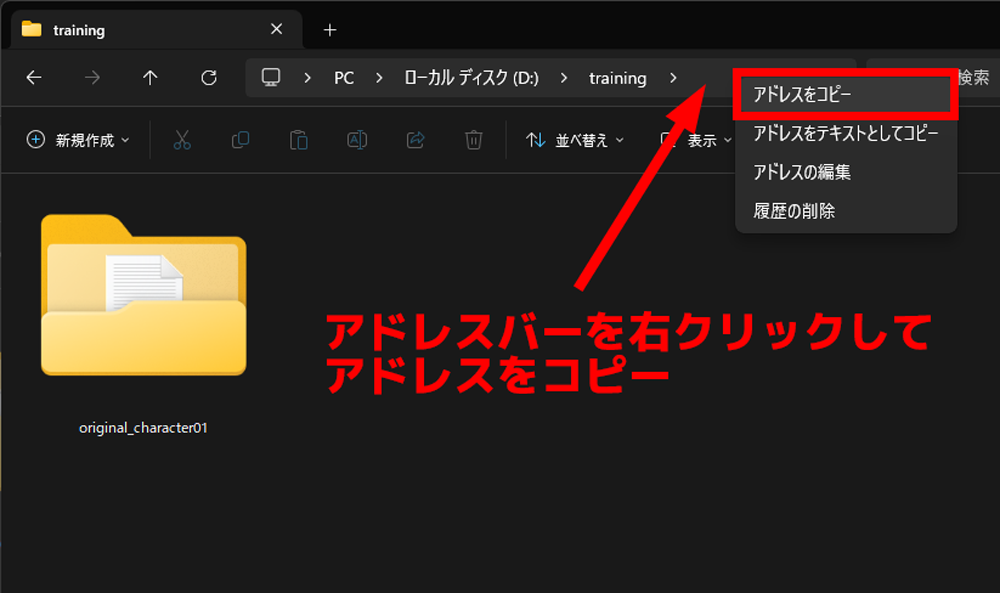
①TrainTrainタブを選択
②preset欄でLoRAを選択
③![]() アイコンをクリックしてLoRAプリセットを適用
アイコンをクリックしてLoRAプリセットを適用
④Model欄でModel(Checkpoint)を選択
この例では、LoRA作成に適していると評判の anyloraCheckpoint を使用します。
⑤上記⓪でコピーした画像フォルダの一つ上の階層のアドレスを貼り付け
⑥lora trigger word欄にトリガーワードを入力
LoRAを適用して画像生成する際、プロンプトに記述するトリガーワードを入力します。
ここでは、orichara01 というトリガーワードにしました。
※この例のようにトリガーワードに01、02のような連番を付けることは、お勧めしません。単に、orichara などにした方が良いでしょう。
⑦image size(height, width)欄に学習させる画像のサイズを入力
今回は、1024*1024 の画像を用意したので、1024 にします。
⑧save lora name欄にLoRAのファイル名を入力
この例では、TrainTrain_Test_v1 というファイル名にしました。
⑨save as jsonを選択(任意)
⓪~⑧で設定した内容を json というファイル形式で保存しておきます。
jsonファイルは、以下のフォルダに保存されます。
/stable-diffusion-webui/extensions/sd-webui-traintrain/jsons/日付フォルダ
次回以降は、各設定を保存したjsonファイルで読み込むことができます。
⑩Start Trainingボタンをクリック
Start Trainingボタンをクリックすると学習が始まります。
今回は、ほぼ標準設定のままLoRAを作成しました。主な項目と使用したグラフィックボード・メモリ容量について記載しておきます。
- 画像枚数:16枚
- 画像サイズ:1024*1024
- train iterations(反復回数):1000(標準値)
- train batch size:2(標準値)
- グラフィックボード:NVIDIA Geforce RTX4060Ti(16GB)
- メモリ:32GB
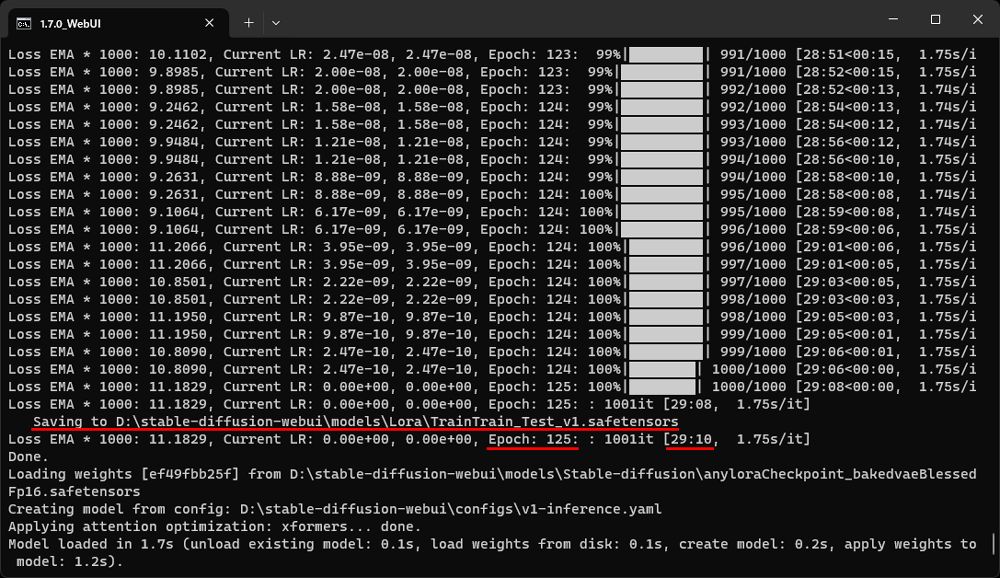
この設定と環境で学習にかかった時間は、29分10秒でした。
エポックは、125となっています。
kohya_ssなどを使用してLoRAを作成する場合は、以下の計算式で学習ステップ数を決める必要がありましたが、今回使用したTrainTrainでは、繰り返し数やエポックを指定する必要はなく、train iterations(反復回数)の値を指定するだけなので非常に簡単です。
画像枚数 × 繰り返し数 × エポック = 学習ステップ数
また、作成されたLoRAを所定のフォルダ /stable-diffusion-webui/models/Lora に自動保存してくれるので、ファイル移動などの手間が省けます。
8.検証
学習時間約30分で作成したLoRAは、いかがなものか?
早速、画像を生成してみましょう。
単純なプロンプトに作成したLoRA(TrainTrain_Test_v1)を強度1で適用して、20枚連続で生成して検証してみました。
容姿や服装に関しては、何も指示していません。
・プロンプト
orichara01, best quality, masterpiece, 1girl, smile, full body, standing, solo, white background, simple background, <lora:TrainTrain_Test_v1:1.0>,
・ネガティブプロンプト
EasyNegativeV2, painting by bad-artist-anime, bad-hands-5
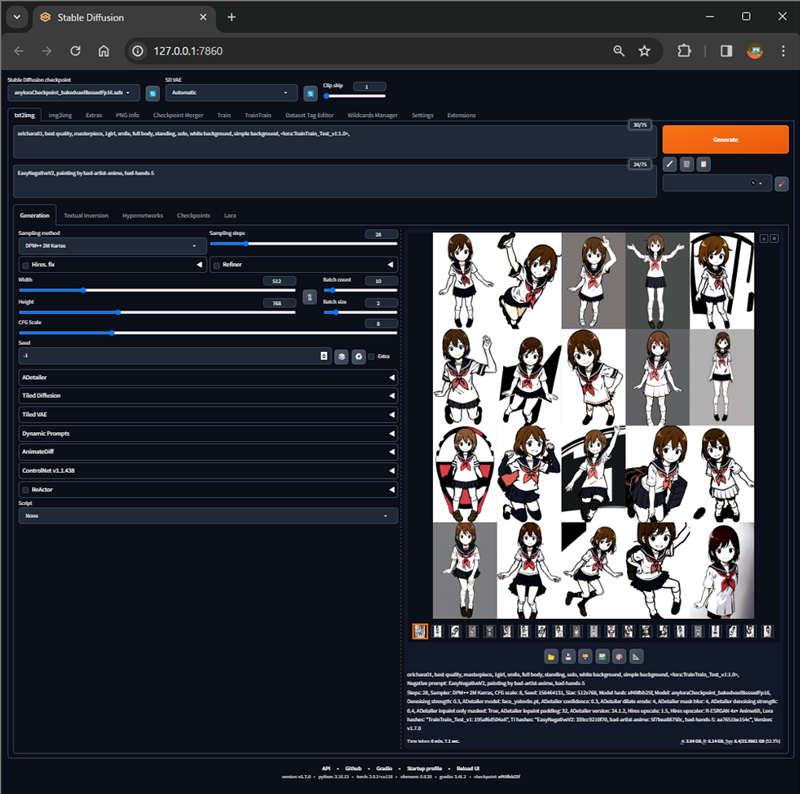
背景に余計な模様が出ているのと病的に色白な画像となっています。また、from above(上からのアングル)を強く学習している感じがします。
顔、髪型、服装などキャラクターに関しては、まずまずといった感じです。
ほぼ標準設定で作成したLoRAですが、しっかりと学習しています。
プロンプトを調整して生成すれば、もう少しマシな画像が生成できる可能性があります。
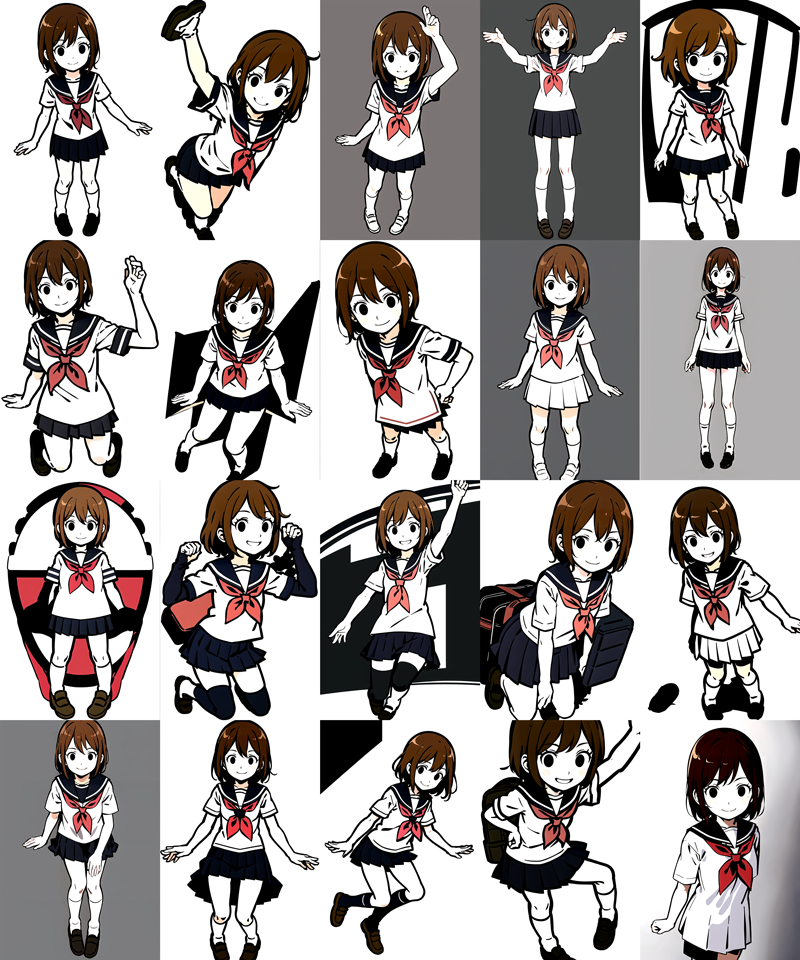
次にX/Y/Z plot(Prompt S/R)で強度0~1まで、0.2ずつ強くしながら生成して比較してみます。
強度0(一番左の画像)は、LoRAが適用されていない状態なのでAnyloracheckpointのキャラクターになっています。強度が上がるにつれて学習効果が表れていますが、それと同時に肌の色が抜けているのが分かります。
顔や服装、体型などに関しては満足のいく結果となりましたが、肌の色がダメですね。
確かに、学習画像を見返してみると肌の色が薄い感じは否めません。
学習画像の修正や差し替えが必要であることが判明しました。。。
画像の準備で手を抜くと、こういう結果となります。

下の画像は、学習画像の肌色を調整してから作成したLoRAの結果です。
LoRA作成時の各パラメータは、前回と全て同じにして作成しました。
肌色が改善されています。

9.まとめ
今回は、TrainTrainの細かな設定変更をせず、ほぼ標準設定のままでLoRAを作成しました。
標準設定のままでも、検証結果のように与えられた学習画像を忠実に学習してることがお分かりいただけたと思います。
TrainTrainでのLoRA作成は、外部ツールを使用せずWebUIで全て完結するので、他のツールに比べて分かりやすくて便利だと思います。また、設定項目がかなり精選されているので、他のLoRA作成ツールより扱いやすいと思います。
LoRA作りに興味をお持ちの方は、ぜひチャレンジしてみてください。
最後までお読みいただき、ありがとうございました。
高機能画像編集アプリ「Photopea」の概要
「Photopea」を導入することで、「Stable Diffusion web UI」の拡張機能タブを開くだけで高機能のペイントツールが利用できるようになります。
それに加えて「Stable Diffusion web UI」の各機能と連携を図ることで、画像編集と画像生成の無駄をなくして、AI画像生成を実現することが可能になります。
「Photopea Stable Diffusion WebUI Extension」の概要
「Photopea Stable Diffusion WebUI Extension」の概要は以下のページで確認することができます。
「Photopea Stable Diffusion WebUI Extension」の導入
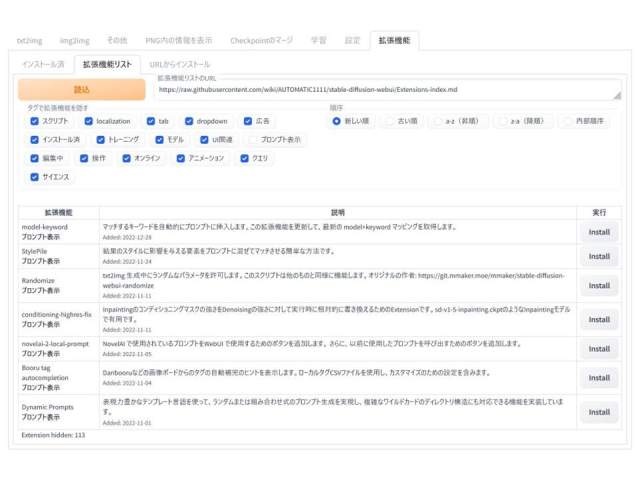
「Photopea Stable Diffusion WebUI Extension」は2023年6月10日時点では「拡張機能リスト(Available)」に掲載されていません。
したがって、この拡張機能は「拡張機能(Extensions)」タブ内の「URLからインストール(Install from URL)」から直接インストールしなければなりません。
拡張機能の詳細は以下のページをご覧ください。
ここからはインストールの手順を紹介していきます。
以下の URL を「拡張機能のリポジトリのURL(URL for extension’s repository)」に入力します。
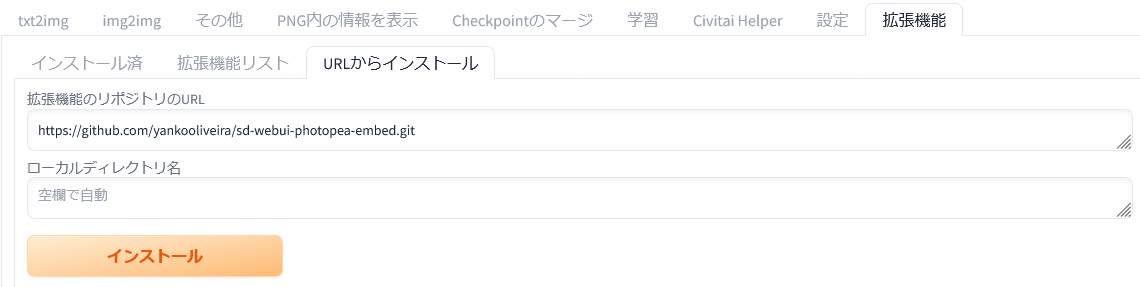
拡張機能の URL が入力できたら「インストール(Install)」ボタンをクリックします。

インストールはすぐに完了します。ボタンの下に「Extensionsフォルダにインストールしたのでインストール済タブから再起動してください」というメッセージが表示されます。

それから「インストール済(Installed)」タブに切り替えて、「適用してUIを再起動(Apply and restart UI)」をクリックします。
これで拡張機能が利用できるようになりました。

インストールが正常に終了している場合は、生成ボタンの上あたりに「Photopea」というタブが出現しています。タブを切り替えることで「Photopea」が埋め込まれた画面が開いて、画像編集を「Stable Diffusion web UI」上で行えます。
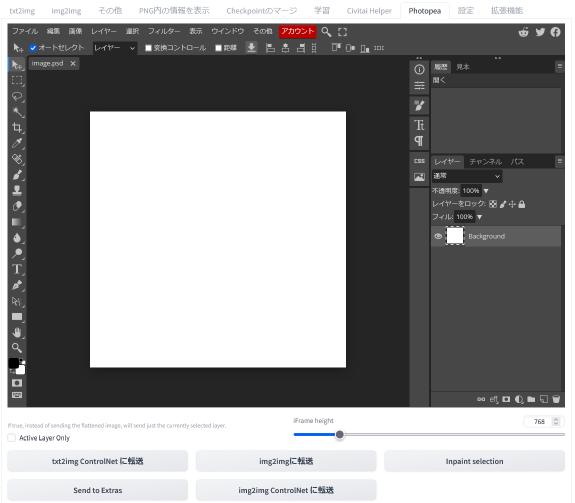
こちらが「Photopea」の画面です。一般的な画像編集アプリと同じような項目がメニューバーにあります。左側には種々のツールが並んでいます。レイヤー機能も右側に備わっています。
また、キャンバスの下には画像を各所へ転送するためのボタンがあります。このボタンで編集した画像を「img2img」等に送ることができます。このボタンは「ControlNet」への転送にも対応しています。
このような高機能な画像編集アプリが「Stable Diffusion web UI」上で手軽に利用できます。このことはAI画像生成と生成画像の編集において利便性が飛躍的に向上したことを意味しています。
AI画像の編集に限って言えば「Photopea」を導入していれば「Photoshop(フォトショップ)」「Illustrator(イラストレーター)」「GIMP(ギンプ)」などの画像編集アプリがなくても何とでもなりそうです。とはいえ、主要な機能を使いこなすだけでも大変そうです。
ここからは「Photopea」の使用例を取り上げます。実際のところ画像編集アプリは使い方に決まりがあるわけではありませんし使用場面はいくらでも想定できます。
また「ControlNet」と連携させて画像をやり取りすることで手間を減らして画像編集と画像生成を行うことも可能です。「ControlNet」の導入方法と基本的な使用方法は以下のページをご覧ください。


超高機能画像編集アプリ「Photopea」を「Stable Diffusion web UI」で利用する
「Photopea Stable Diffusion WebUI Extension」の利用
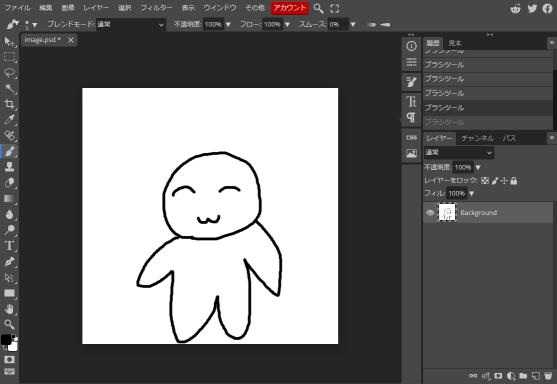
キャンバス上にイラストを取り込んだり、ブラシを使って絵を描いたりすることができます。
各種ツールと画像をやり取りなどの機能を試すために、マウスを使って簡単な人型を描いてみました。ちょっと触った印象として、ペイントツールは本当に優れていると感じました。なお、板タブが見つからなかったため、ペンタブレットが使えるかどうかは試していません(多分大丈夫だとは思いますが)。
(^ω^)
U U
U U
余談ですが「Stable Diffusion web UI」を始めてから久方ぶりにマウスで絵を描いてみたのですが、マウスがまったく思いどおりに動かず、文字さえまともに書くことができませんでした。パソコンに初めて触った頃はペイントでよく遊んでいたような記憶があります。
さて、画像を編集したら「img2img」等の任意の場所に送ります。

描いたイラストや編集後の画像は「txt2img ControlNet に転送」「img2imgに転送」「Inpaint selection」「Send to Extras」「img2img2 ControlNet に転送」などのボタンで各所に転送することができます。
「Photopea」から画像を転送する際は、必要に応じて画面下の「Active Layer Only」にチェックを入れてください。
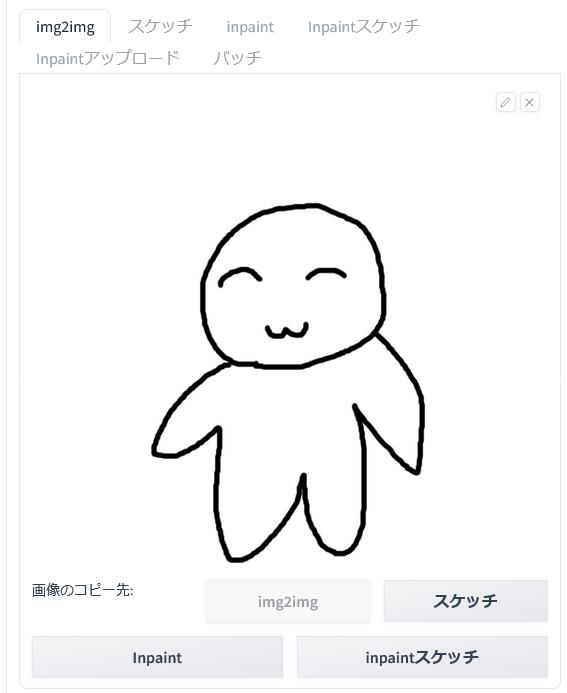
ここでは「img2img」に転送してみました。ボタンひとつで画像が転送されます。
あとはいつものように設定するだけです。
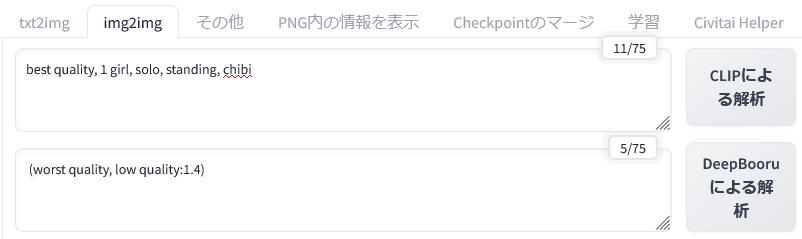
ここでは「ちびキャラ」の画像を生成してみようと思います。そのために最低限のプロンプトである「chibi」を入力しておきます。
そして、「生成」ボタンをクリックします。
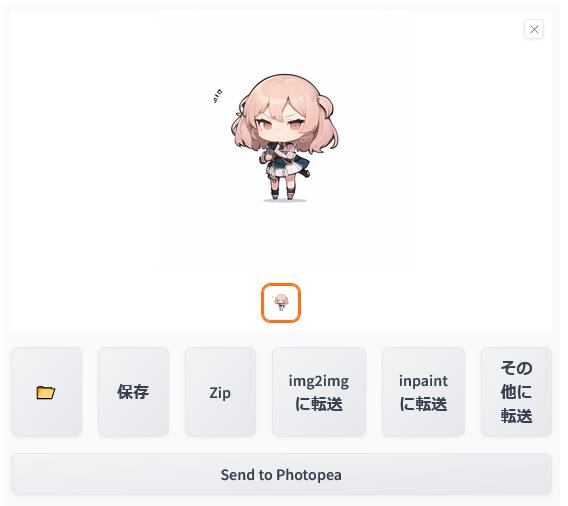
このような画像が生成されました。
ここで生成された画像の下にある「Send to Photopea(フォトピーに転送)」をクリックしてみます。
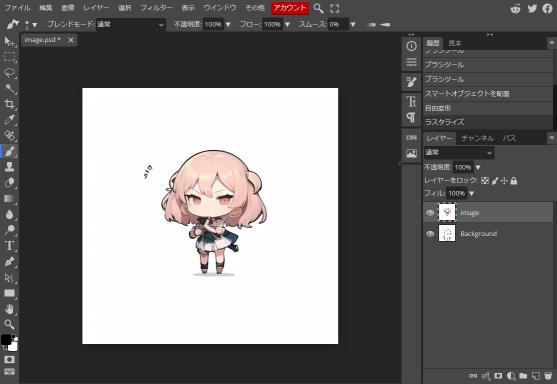
先ほど生成された画像が「Photopea」のキャンバスに表示されています。ここでさらに画像を編集することができます。
「Photopea」の使い方を理解するために、あえて画像を加工してみましょう。
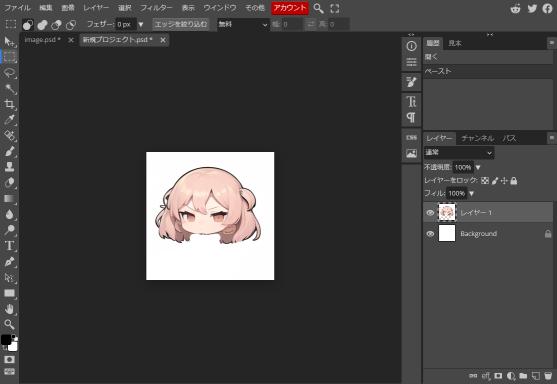
顔だけを抜き出してキャンバスサイズも小さくしてみました。
この画像を再び「img2img」に転送します。
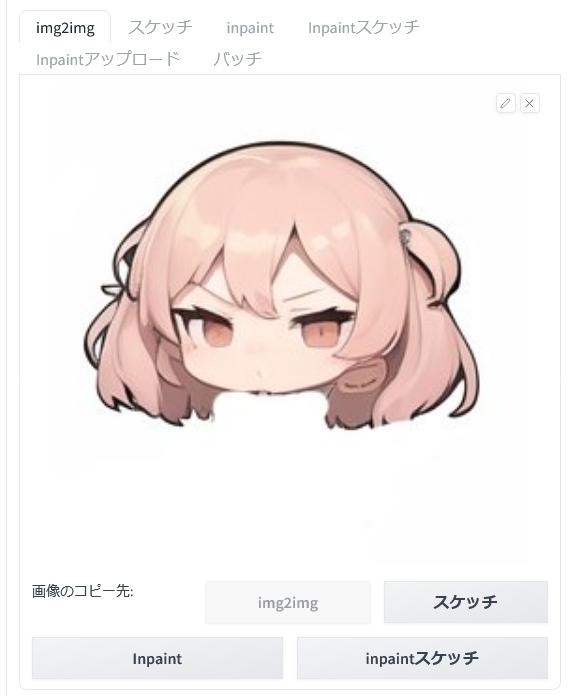
先ほどの画像が「img2img」に転送されてきました。
編集で削除した首の部分に違和感があります。また、このキャラクターは表情が怒っているように見えるので笑顔に変えてみましょう。

最初のプロンプトに「smile」を付け足します。そして「生成」ボタンをクリックします。
「standing」は消しても良かったかもしれませんが忘れていました。
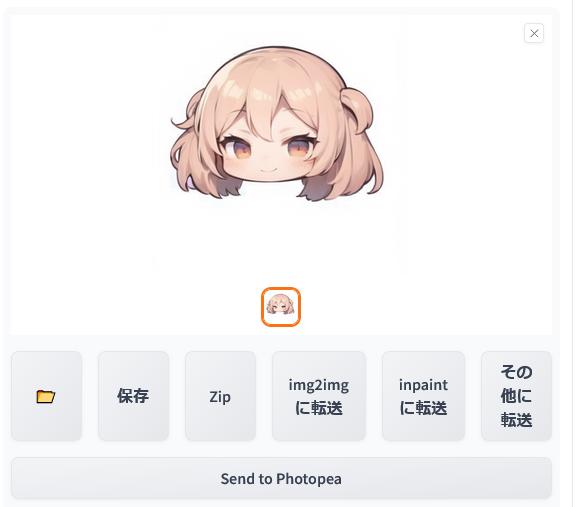
すると、このような画像が生成されました。先ほどよりも柔和な表情をしており、「smile」というプロンプトが反映されていることが窺えます。
今度はこの画像を「Photopea」に一旦送ってから、未編集のまま「txt2img ControlNet に転送」してみます。
この画像を転送したり編集したりする必然性は特にないのですが、「Photopea」の使い方を理解するためにあえてやっています。

「ControlNet」との連携を図る
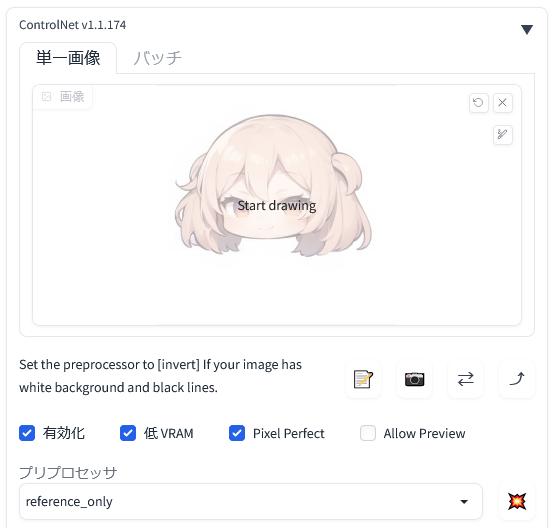
画像を「Photopea」から「txt2img ControlNet に転送」機能を使って「ControlNet v1.1.XXX」に転送しました。
「ControlNet」を「有効化(Enable)」して「低VRAM」と「Pixel Perfect」もついでにチェックしておきます。そして、プリプロセッサに「reference_only」を指定してみます。
なお、「ControlNet」を利用するためには当然のことながら「ControlNet」という拡張機能がインストールされていることが前提となります。
「ControlNet」と「reference only」の使い方は以下のページをご覧ください。

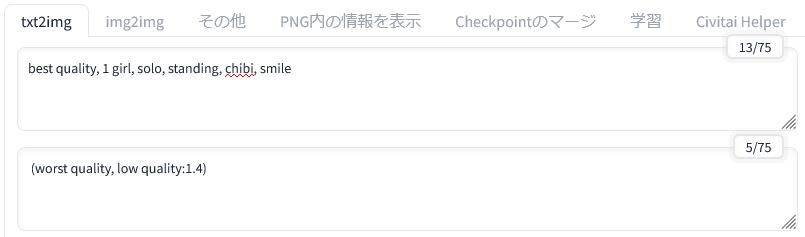
プロンプトは先ほどと同じものを入れています。プロンプトは必要に応じて変更してください。
それから「生成」ボタンをクリックします。
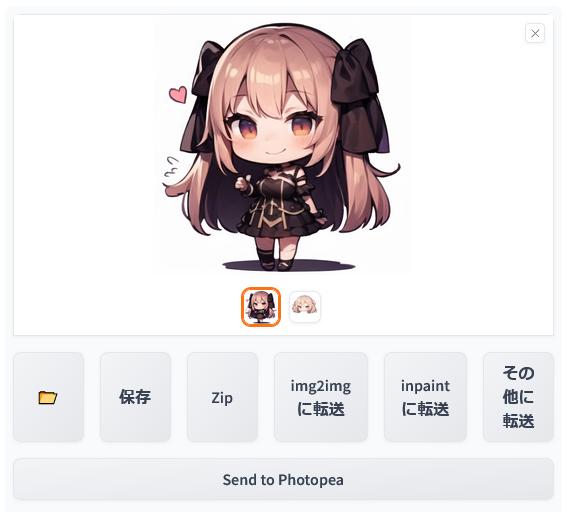
そうすると、このような画像が生成されました。

生成される画像によっては「Control Mode(コントロール・モード)」を「ControlNet」重視に変えて様子を見てもよいかもしれません。またはプロンプトの内容次第ではプロンプト重視にしてもよいと思います。
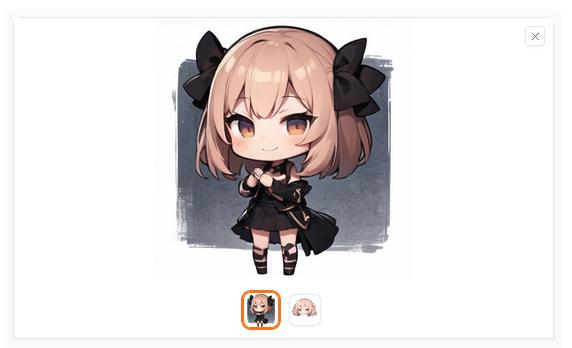
「Control Mode(コントロール・モード)」を変更しても劇的な違いが見られないこともあります。AI画像生成は時間をかけて試行錯誤するしかありません。
次に、プロンプトの効果を確認するために、先に挙げたプロンプトを変更してみました。

今度は「standing」を削除してから「sleeping」と「in the bed」を入れています。
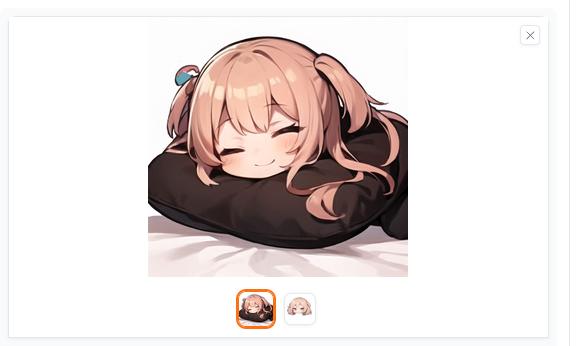
すると、このような画像が生成されました。こういう風に画像編集と画像生成を連続的に行うことができます。
また「reference only」を使用することで同じような画像を連続して生成することも可能です。

これまで見てきたように「Photopea Stable Diffusion WebUI Extension」を導入することで、高機能な画像編集アプリを手軽に利用することができる上に、「Stable Diffusion web UI」の各機能と連携して編集後の画像を用いて即座に画像生成を行うことが可能になります。
これは高価な編集アプリが不要になるだけでなく、画像の面倒なやり取りを避けることができるようということです。AI画像生成の利便性が格段に高まったといえます。この拡張機能はぜひ一度お試しください。
拡張機能「HakuImg」とは?

Stable Diffusion web ui の拡張機能です。
画像にさまざまな編集を加える事ができます。

拡張機能「HakuImg」の導入方法
Google Colabとローカル環境では導入の仕方が異なります。
・Google Colabの方は立ち上げ時に以下のコードを挿入して下さい。
%cd /content/stable-diffusion-webui/extensions/
!git clone https://github.com/KohakuBlueleaf/a1111-sd-webui-haku-img /content/stable-diffusion-webui/extensions/a1111-sd-webui-haku-img
%cd /content/stable-diffusion-webuiWebUIを起動した時に、HakuImgのタブが追加されていれば導入成功です。
・ローカル環境の方は「Extensions」→「Install from URL」の「URL for extension’s git repository」に下記のURLを入力しInstallをクリックしましょう。
https://github.com/KohakuBlueleaf/a1111-sd-webui-haku-img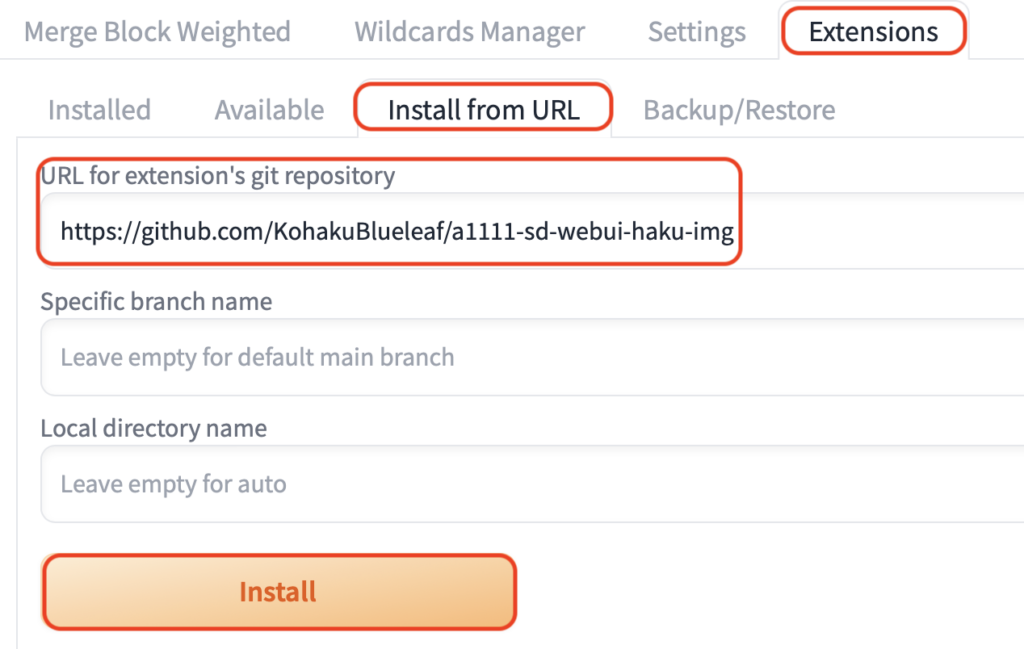
インストールできたら、1度リロードして下さい。
- Stable Diffusionのプロンプトの見本が知りたい
- 画像生成が思ったようにできない
- 色々なプロンプトを探したい
など、画像生成AIのプロンプトに関する疑問が解決するかもしれません。

拡張機能「HakuImg」の使い方
機能が多いので、全部を覚える必要はありません。基本となるのは「Effect」で加工する事と、「Effect」で編集した画像を「Blend」で重ねることです。
Blend
各Layerに入れた画像を重ねる事ができます。
どのように重ねるかは「Blend mode」で指定します。「Blend mode」はたくさんの種類がありますが、公式にも説明がないので、使ってみて判断して下さい。基本的にはデフォルトの「normal」で普通に重ねられます。
inpaintと同じように画像にマスクをかけることもできます。
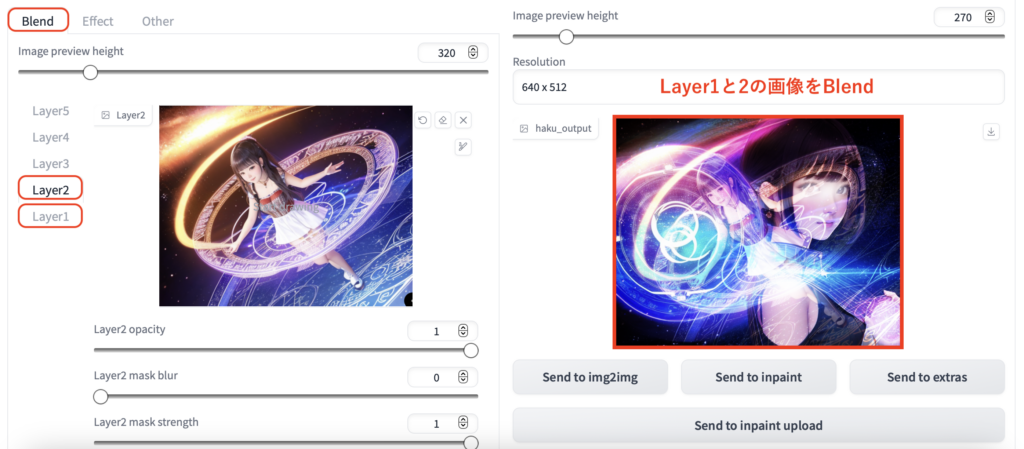
opacity(不透明度)、mask blur(マスクのぼかし具合)、mask strength(マスクの強さ)が設定できます。
この後説明する「Effect」と組み合わせて画像を加工していきます。
加工した画像を inpaint や extras へ送ることもできます。
Effect(Color)
色調の調整ができます。
temperature(温度)、brightness(輝度)、saturation(飽和)、ExposureOffset(オフセット照射)、Noise(ノイズ)、hue(色相)、contrast(コントラスト補正)、gamma(ガンマ補正)、Vignette(周りのボカシ)、Sharpness(シャープさ)、HDR(輝度)の11項目の調整ができます。
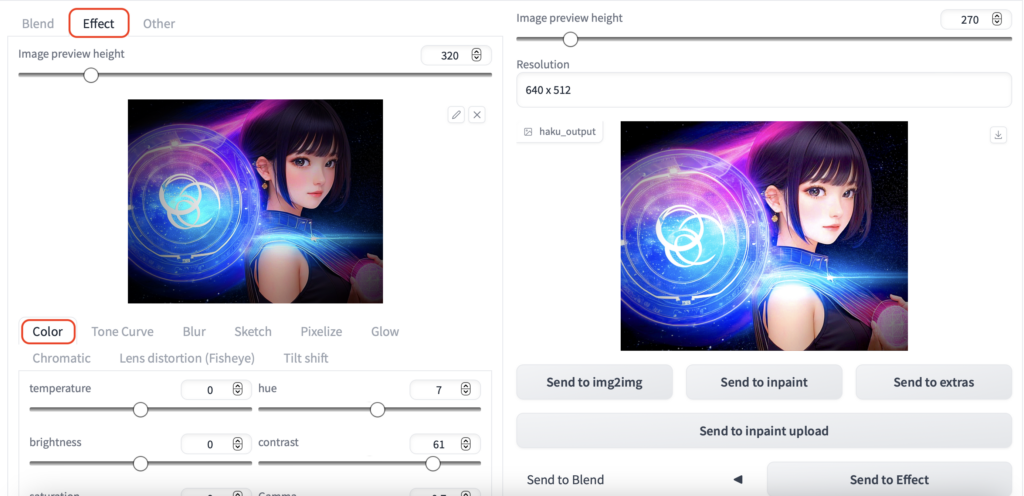
基本的な画像の加工はここに大体揃っています。
ここだけ使えれば十分な気もしますが、「HakuImg」は非常に多機能です。
まだまだいろいろな事ができます。
Effect(Tone Curve)
画像の明るさや明暗の比率(コントラスト)を調節するためのものです。
曲線を使って思い通りに調節できるのがトーンカーブです。
3つのポイントを操作して、画像のコントラストを調整します。
元々明るい所をより明るく、暗い所をより暗くすると、コントラストがはっきりとした画像になります。
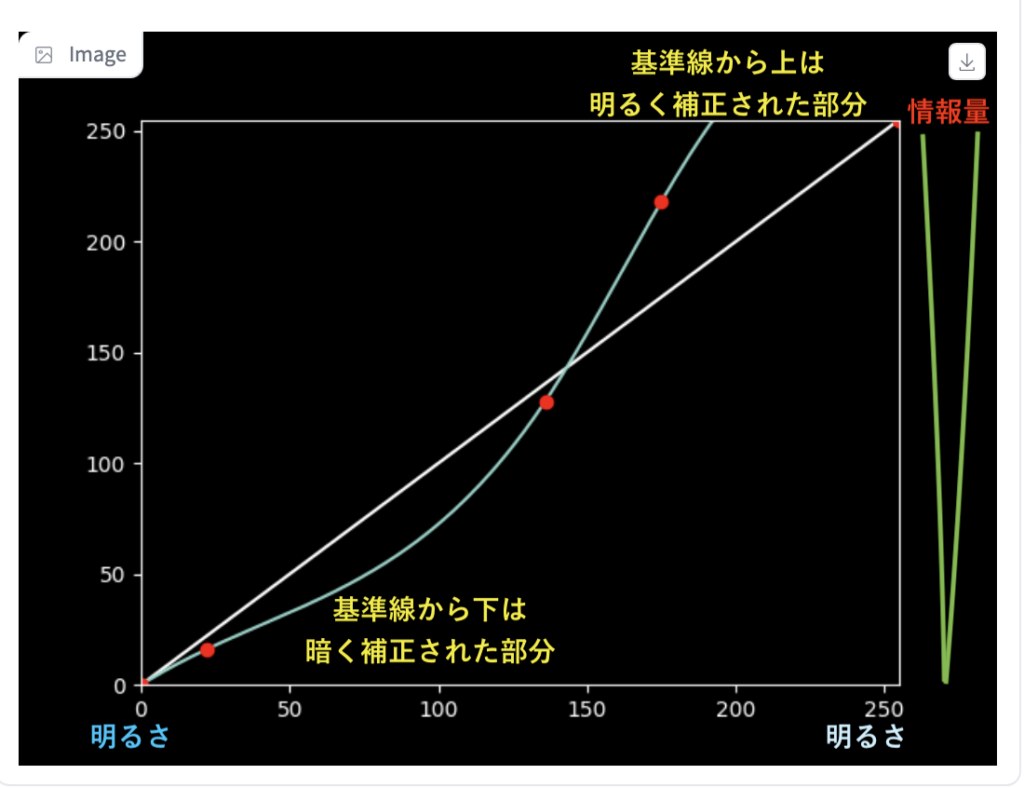
試しに1枚、コントラストを強調してみました。
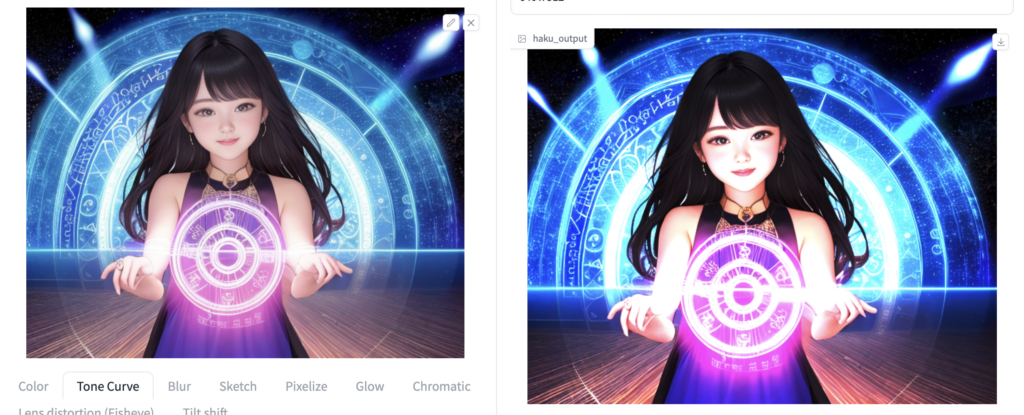
いかがでしょうか?
より光っているように見えますね。
こんな本格的な画像加工機能が、無料で使えるのはすごいです。
Effect(Blur)
画像をボカシます。
Blendのレイヤーと組み合わせてボカシた画像と、マスク加工した画像を重ねたりもできます。
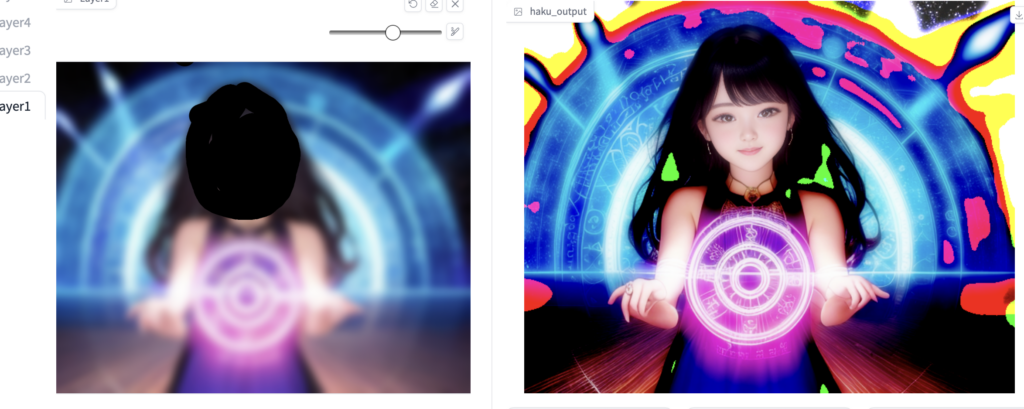
こんな画像も作れます(Blend mode : darkenを使用)
Effect(Sketch)
画像から線画を抽出できます。
先ほどのようにできた線画をレイヤーに送って合成すると

アウトラインが強調され、印刷物のような画像を生成できます。
線画はグレーとカラーを選択できます。
Effect(Pixelize)
ピクセル加工をします。


こんな感じでモザイク処理みたいなこともできます。
Effect(Glow)
画像の発光具合の調整です。

なんだか色っぽくなりました・・・
これもレイヤーに送って画像を重ねると、一部だけ輝いているような画像を作れます。
chromatic
画像をずらして色収差を作ります。ブラー機能でぼかしを入れることもできます。


あんまりマジマジと見ると酔いそうです。
Lens distortion(Fisheye)
魚眼レンズで撮影した写真のように、画像を歪ませます。
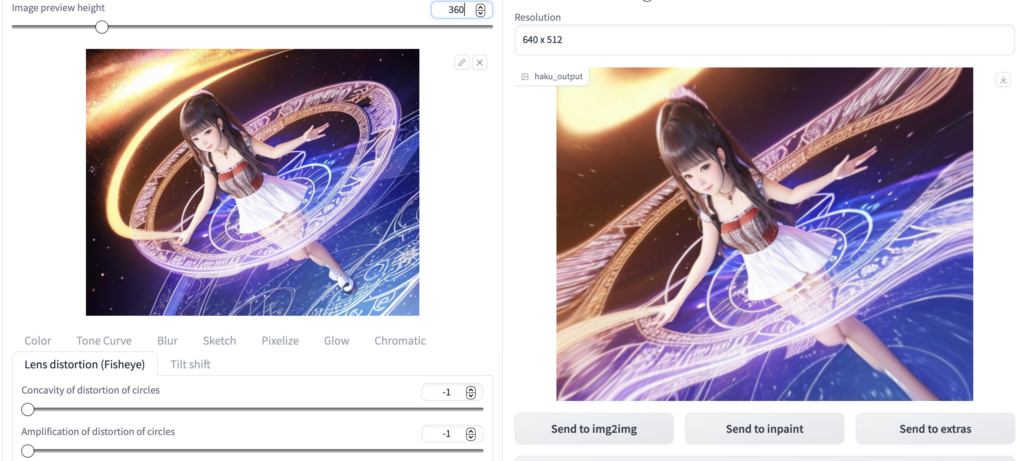
実写モデルでやれば、「こだわって魚眼レンズで撮った自撮り画像」みたいな画像も生成できそうですね。
Tilt shift
ピントと遠近感の調整ができます。
Y軸への影響の位置決めをして、フォーカス領域の幅(ピクセル単位)を調節します。
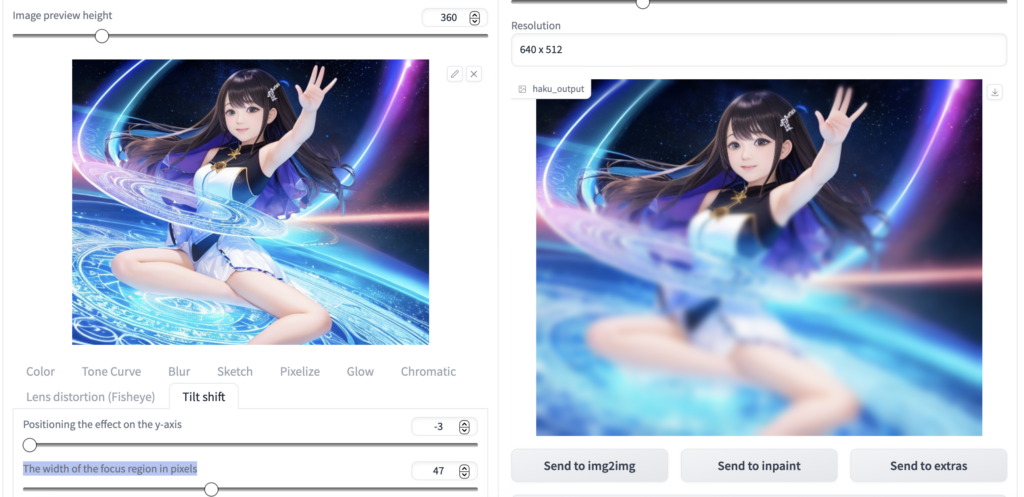
下半身にボカシを入れてみました。
逆に顔だけボカシを入れることもできます。
Other
画像の上下左右の端を引き伸ばす事ができます。
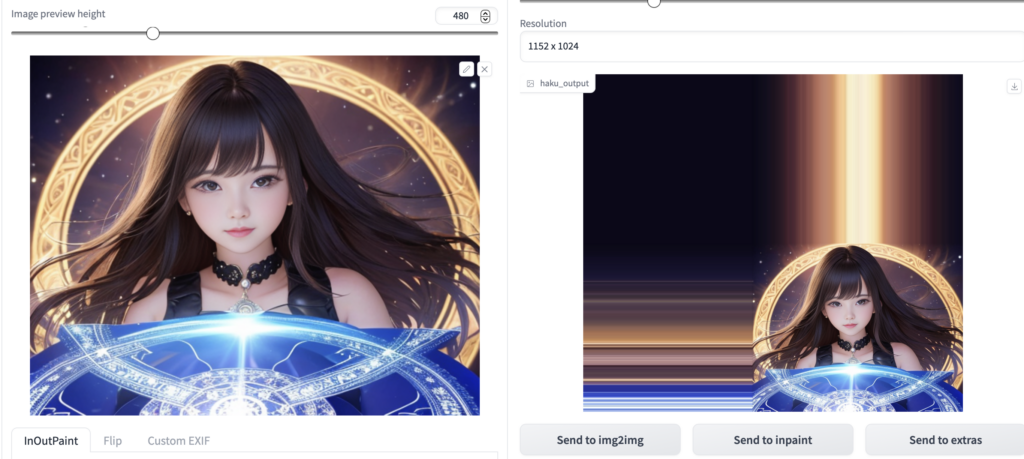
画像を加工してポスターにしたり、商品のパッケージになりそうです。
Stable Diffusionの『ワイルドカード』とは?
Stable Diffusion web ui の拡張機能「dynamic-prompts」の機能の一つで、テキストファイルの中からランダムにプロンプトを拾って画像を生成できます。
ある程度決まったパーターンの画像をバージョン違いで生成する必要がある時や、服装だけ、髪型だけ、背景だけなどランダムに変えたい時にとても有用です。
詳細はこちらのURLからご確認ください。
『ワイルドカード』の使い方
それでは、具体的に『ワイルドカード』の使い方をみていきましょう!
①Stable Diffusion Web UIを立ち上げる
Stable Diffusion Web UI を立ち上げてください。
もしも、まだ使用環境が整っていない方がいたら、この記事を参考にして環境を構築してください。

②拡張機能「dynamic-prompts」を導入する
拡張機能「dynamic-prompts」の導入は以下の手順となります。
- Stable Diffusion の Extensions のタグを選択
- Install from URL を選択
- URL for extension’s git repositoryに以下のURLを貼り付け https://github.com/adieyal/sd-dynamic-prompts.git
- Installをクリック
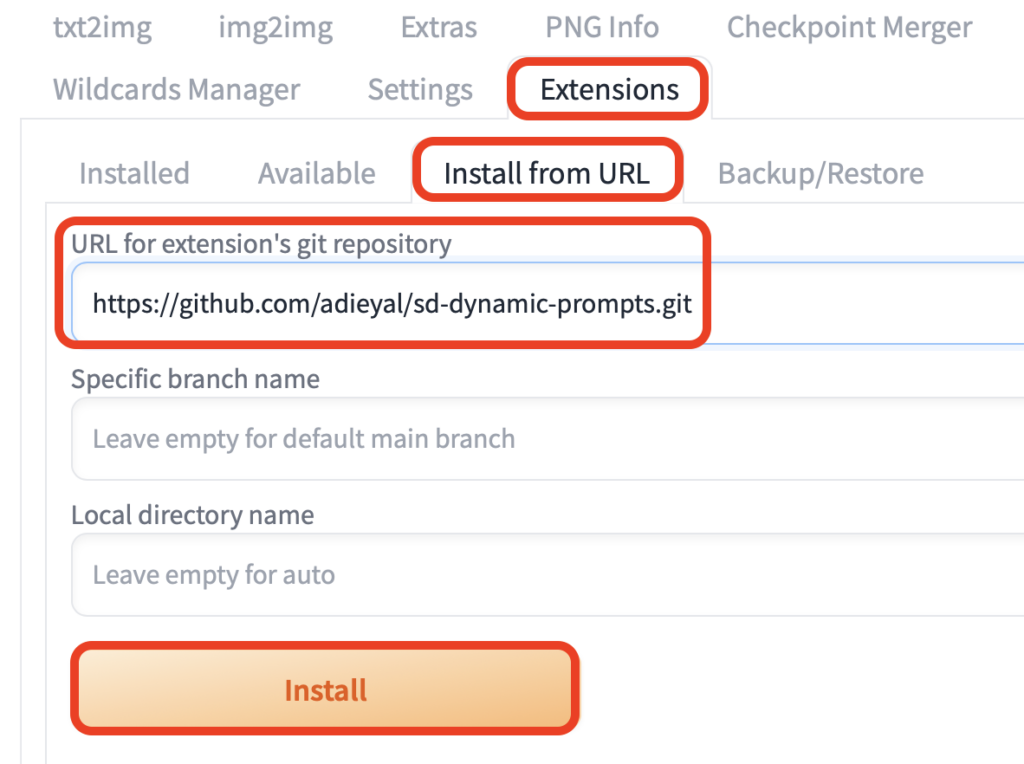
「dynamic-prompts」のダウンロードはこれで終了です。
1度リロードをしてください。
③『ワイルドカード』用のファイルを導入する
『ワイルドカード』を使用するには事前にテキストファイルの準備が必要です。dynamic-promptsから呼び出せるワイルドカードもありますが、あまり実用性はありません。実用的なものはCIVITAIに作成済みのテキストファイルがいくつか無料配布されていますので、それを使う方法もあります。以下はCIVITAIからダウウンロード可能なワイルドカードの一部です。
代表的なワイルドカード
- 200+ Wildcards – https://civitai.com/models/20868/200-wildcards-nsfw-and-sfw
- Clothes wildcards – https://civitai.com/models/73184/clothes-wildcards
- Wildcards – Camera Views – https://civitai.com/models/24940/wi
- Advanced Wildcards – 1950s Kit – https://civitai.com/models/70930/advanced-
- SDVN-Wildcards – https://civitai.com/models/101753/sdvn-wildcards
ダウンローとしたテキストファイルは「stable-diffusion-webui」>「extensions」>「sd-dynamic-prompts」>「wildcards」フォルダの中に入れてください。
④『ワイルドカード』を使う・作る
試しにdynamic-promptsのデフォルトで呼び出せるワイルドカードを使ってみましょう。
上部タグからWildcards Manager を選択します。
Collection Actions を開き、今回はartistsを選択し Copy Collection を押します。
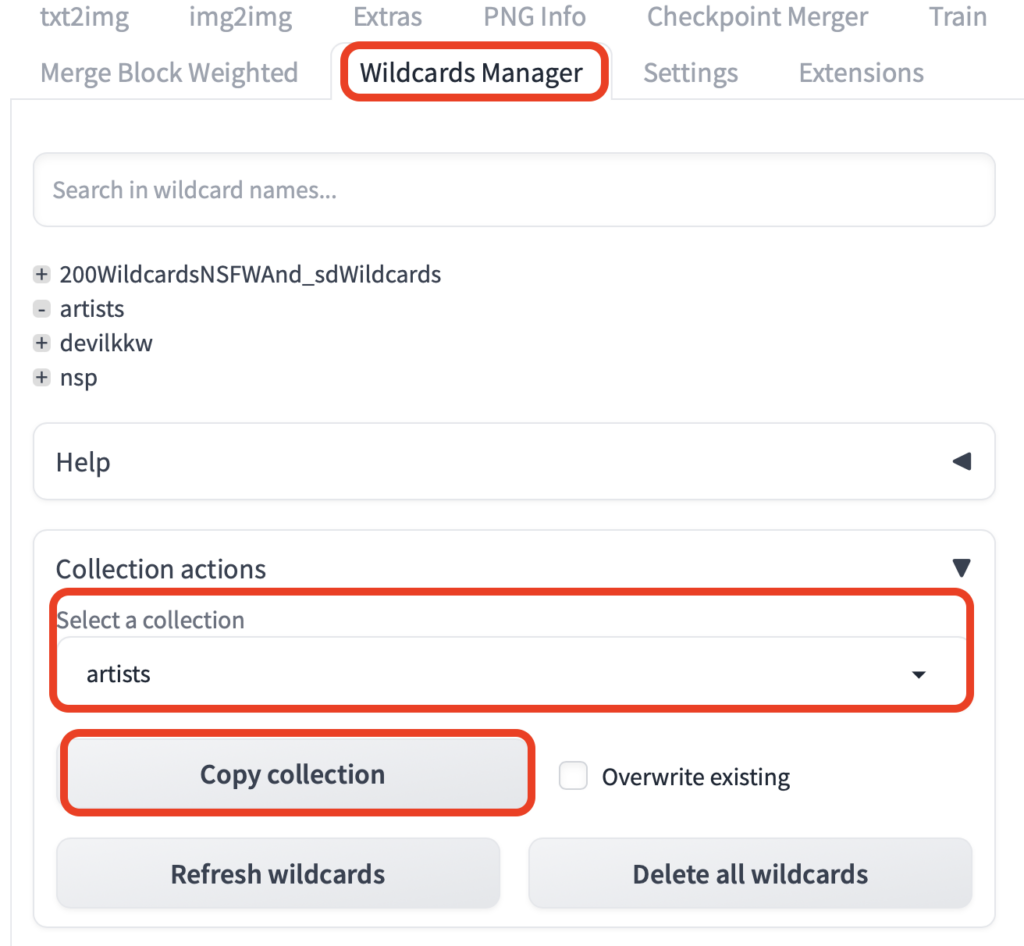
これでartistsのファイルが呼び出しできました。
このartistsを開いていくとartists/Japanese Art/ukiyoeのワイルドカードがあるのでこれを使って画像を生成していきます。
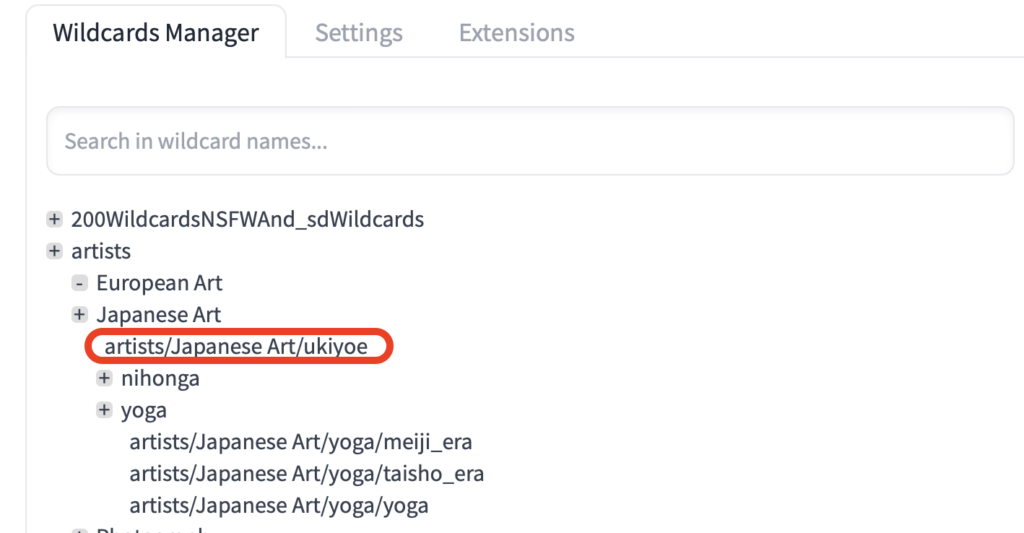
ワイルドカードを使うためには、専用の構文を使う必要があります。
__ワイルドカード名__左右のアンダーバーはそれぞれ2本連続で記述してください。
ではtxt2imgで画像を生成します。プロンプトは
__artists/Japanese Art/ukiyoe__Batch sizeは6にしました。
次にdynamic-promptsのパラメーターを設定します。
Dynamic Prompts enabled – 有効・無効のスイッチです。有効にします。

以上の条件で画像を生成すると、

それぞれの画像はワイルドカードartists/Japanese Art/ukiyoe内にあったものから選択されます。生成された画像のプロンプトはそれぞれ
Miyagawa Chōki, Tsukioka Yoshitoshi, Katsushika Ōi, Toyohara Kunichika, Torii Kiyohiro, Tsukioka Yoshitoshi
となります。(モデルが学習できいないものは表現できないようです。)
また、ワイルドカードは自分で作成した物を使うことができます。その場合は通常のテキストファイルで作成しても良いですし、Wildcards Manager のタグから既存のワイルドカードを編集して使うこともできます。
- Stable Diffusionのプロンプトの見本が知りたい
- 画像生成が思ったようにできない
- 色々なプロンプトを探したい
など、画像生成AIのプロンプトに関する疑問が解決するかもしれません。
テキストファイルを使わないで『ワイルドカード』を使用する場合
dynamic-prompts はワイルドカードを使わないで、プロンプトの中からランダムで選択できるdynamic-prompts 専用の構文があります。
最も基本的な構文(呪文A~Cの中からランダムに1つだけ選ぶ)は次のとおりです。
{ 呪文A | 呪文B | 呪文C }
呪文を半角の|で区切り、それを半角の{}で囲むだけです。
Dynamic Prompts enabled を有効化し、プロンプトに
{ cat | dog | bird }
このように書くと

cat , dog , bird から一つが選択された画像が生成されます。
①複数を選択する
呪文の中からランダムに複数を選択することもできます。その場合の構文は次のとおり。
{ 選択する数 $$ 呪文A | 呪文B | 呪文C }
具体例は次のような感じです。
a girl { 2$$ glasses | earrings | hair ribbon}
この場合は、メガネ、イヤリング、リボンの中から2つ選択された画像が生成されます。

②「and」で結合する
My favourite ice-cream flavours are {2$$ and $$chocolate|vanilla|strawberry}
このように書くと、2$$ と $$ の部分にそれぞれ1語が選択され
- My favourite ice-cream flavours are chocolate and vanilla
- My favourite ice-cream flavours are chocolate and strawberry
- My favourite ice-cream flavours are vanilla and chocolate
- …
のようにandで結合されたプロンプトで画像を生成することができます。
③選択する数をランダムにする
以下の構文で選択数をランダムにすることができます。
My favourite ice-cream flavours are {1-2$$ and $$chocolate|vanilla|strawberry}
このようにプロンプトを描いた場合
- My favourite ice-cream flavours are chocolate
- My favourite ice-cream flavours are strawberry
- My favourite ice-cream flavours are vanilla
- My favourite ice-cream flavours are chocolate and vanilla
- My favourite ice-cream flavours are chocolate and strawberry
- My favourite ice-cream flavours are vanilla and chocolate
- …
このように1語もしくは2語を選択したプロンプトで画像が生成されます。
④重みを付ける
選択されるプロンプトの割合を変更することもできます。
{0.5::summer|0.1::autumn|0.3::winter|0.1::spring}
このように書くと、夏:5 秋:1 冬:3 春:1 の割合で選択されます。
dynamic-prompts については独自の構文がまだまだ沢山あります。詳しく知りたい方は下記のURLで学習してください。

「Wildcards Manager」を使う方法
Wildcards Managerを使うと、ワイルドカードの中から必要なものを探したり、ワイルドカードを編集することができます。
上部ダグからWildcards Managerを選択し、ヘアスタイルを変更できるワイルドカードを探してみましょう。
Search in wildcard namesに “hair” と入力します。
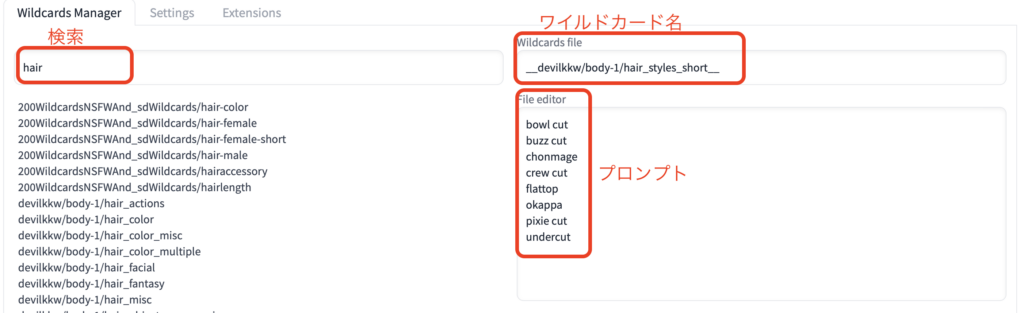
そうすると、髪型に関するワイルドカードの一覧が選ばれます。その中から一つを選びましょう。右側にワイルドカード内のプロンプトが表示されるので、確認しながら今回はdevilkkw/body-1/hair_styles_shorを選びました。
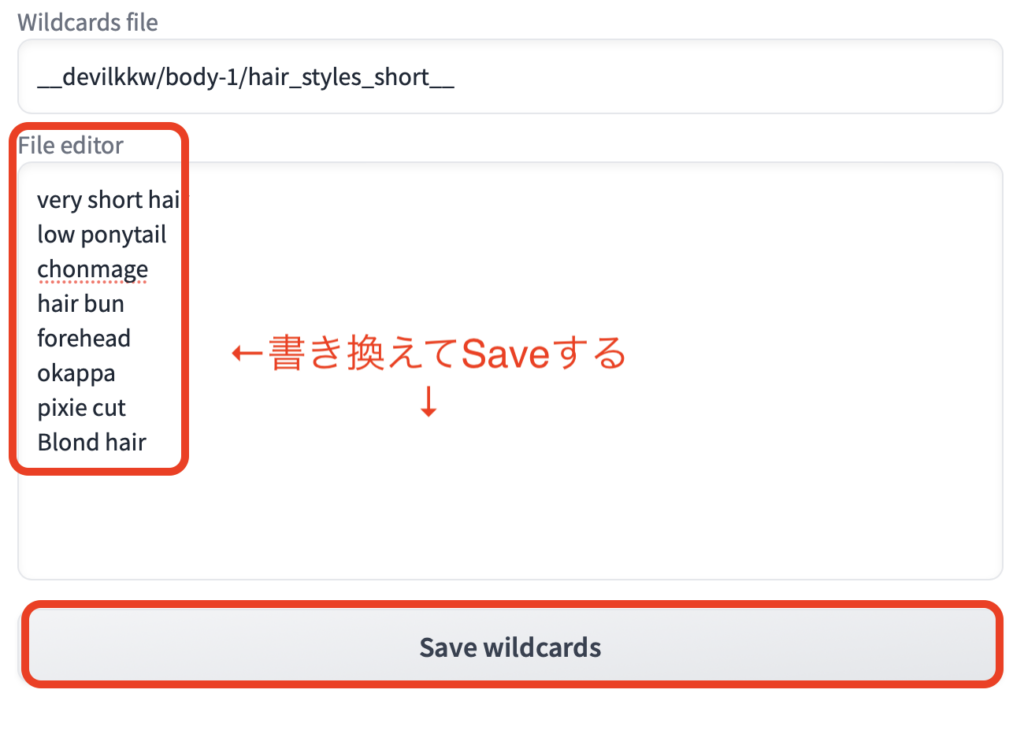
さらに中身も編集してしまいましょう。
File editorをそのまま書き換えて、下にあるSave wildcardsを押します。
これで画像を生成すると・・・

中からランダムに髪型を選んで画像を生成してくれます。
服装のワイルドカードや表情のワイルドカードを作ってしまえば、かなり便利に使えそうですよね。
まとめ
いかがでしたでしょうか?
Stable Diffusionの拡張機能『Dynamic prompts』でワイルドカードを使う方法!について解説してきました。
今回のポイントをまとめると、以下のようになります。
- Dynamic promptsはプロンプトをランダムにできるツールです。
- ワイルドカードを使うと、髪型だけ、服装だけ、表情だけを変えることも可能です。
Dynamic promptsはかなり多機能な拡張機能です。
うまく使いこなせば、きっとあなたの制作を助けてくれると思います。
ぜひ活用してみてください。
コメント